벤디트 문제에서는 에이전트가 어떤 행동을 취하든 다음에 도전할 문제의 설정은 바뀌지 않았다.
그런데 세상의 대부분의 문제는 에이전트의 행동에 따라 상황이 시시각각 변한다.
지금부터 변화하는 상태에 따른 최선의 결정을 돕는 도구, 마르코프 결정 과정에 대해 알아보자.
강화 학습은 분명 스스로 정책을 학습하는 도구이지만, 이와 같이 해석적으로 문제의 해를 증명하는 과정 또한 중요하다.
결국 문제를 잘게 쪼개 해석적으로 문제를 풀고, 이를 통해 큰 문제의 논리적 완결성을 증명해야 하기 때문이다.
이번 장은 아래와 같은 순서로 진행할 것이다.
- 먼저, MDP에서 쓰이는 용어들을 수식으로 정리할 것이다.
- 그 다음, MDP의 목표를 정의한다.
- 마지막으로, 간단한 MDP 문제를 풀며 목표를 달성해본다.
마르코프 결정 과정(MDP)이란?
결정 과정이란, 에이전트가 (환경과 상호작용하며) 행동을 결정하는 과정을 뜻한다.
구체적인 예와 함께 MDP의 성격을 살펴보자.
구체적인 예 - 그리드 월드
먼저 아래 그림을 보자.
세상은 격자(grid)로 구분되어 있고, 그 안에 로봇이 있다.
로봇은 격자 세상에서 오른쪽 또는 왼쪽으로 이동할 수 있다.
지금부터 이 세계를 '그리드 월드'라고 하겠다.

이를 강화학습 용어로 표현하면, 아래와 같다.
- 에이전트
- 로봇
- 환경
- 사과의 위치
- 폭탄의 위치
- 로봇의 위치
이 문제에서는 에이전트가 행동할 때마다 상황이 변한다.
이 상황을 강화학습에서는 상태(state)라고 한다.
MDP에서는 에이전트의 행동에 따라 상태가 바뀌고, 상태가 바뀐 곳에서 새로운 행동을 하게 된다.
위 그림에선 에이전트는 '왼쪽으로 두번 이동'하는 것이 최선의 판단이다.
MDP에는 '시간' 개념이 필요하다. 특정 시간에 에이전트가 행동을 취하고, 그 결과 새로운 상태로 전이한다.
이때의 시간 단위를 타임 스텝(time step)이라고 한다.
타임 스텝은 에이전트가 다음 행동을 결정하는 간격이기 때문에 구체적인 단위는 어떤 문제를 풀려는지에 따라 달라진다.
이번에는 아래 문제를 생각해보자.

에이전트는 눈앞의 보상만 바라보면 +1점을 최대로 얻겠지만,
최선의 선택은 오른쪽으로 두번 이동하여 +6점짜리 사과나무를 찾는 것이다.
이 예에서 알수 있듯이 에이전트는 눈앞의 보상이 아니라 미래에 얻을 수 있는 보상의 총합을 고려해야 한다.
즉, 보상의 총합을 극대화하려 노력해야 한다. (수익)
에이전트와 환경의 상호작용
MDP에서는 에이전트와 환경 사이에 상호작용이 이루어진다.
이때 명심해야 할 사실은 에이전트가 행동을 취함으로써 상태가 변한다는 점이다.
그림으로 표현하면 아래와 같이 된다.

이를 시계열 데이터로 표현하면 다음과 같은 이벤트의 나열로 볼 수 있다.

환경과 에이전트를 수식으로
MDP는 환경과 에이전트의 상호작용을 수식으로 표현한다.
그렇게 하려면 다음의 세 요소를 수식으로 표현해야 한다.
- 상태 전이: 상태는 어떻게 전이되는가?
- 보상: 보상은 어떻게 주어지는가?
- 정책: 에이전트는 행동을 어떻게 결정하는가?
이 각각의 세가지에 대해 알아보자.
상태 전이
상태 전이는 크게 두가지 방식이 있다.
- 결정적 상태 전이
- 확률적 상태 전이
가볍게 느낌을 잡고 싶으면, 양쪽을 표현한 그림을 먼저 보길 바란다.
결정적 상태 전이
먼저 결정적 상태 전이는 아래와 같이, 그 결과로 에이전트가 '반드시' 이동하는 형태이다.

이러한 성질을 결정적(deterministic)이라고 한다.
상태 전이가 결정적일 경우 다음 상태 s'는 현재 상태 s와 행동 a에 의해 '단 하나로' 결정된다.
그래서 수식으로 아래와 같이 표현할 수 있다

그래서 위 수식을 상태 전이 함수 라고 한다.
확률적 상태 전이
반면, 확률적 상태 전이는 함수처럼 정해진 결과를 내뱉지 않는다.

이 그림은 에이전트의 이동을 확률적(stochastic)으로 표현하고 있다.
이처럼 행동이 확률적으로 달라지는 경우는 뭐가 있을까?
- 바닥이 미끄러워서?
- 로봇이 10%의 확률로 고장나서?
여하튼, 에이전트가 상태 s에서 행동 a를 선택한다고 해보자. 이 경우 다음 상태 s'로 이동할 확률은 다음처럼 나타낸다.

이 수식을 상태 전이 확률이라 한다.
마르코프 성질
아까 위에서 이야기 못한 '마르코프'에 대한 의미를 이제야 설명할 수 있을 것 같아 지금 이야기하겠다.
상태 전이 확률 p가 다음 상태 s'를 결정하는 데는 '현재' 상태 s와 행동 a만이 영향을 준다.
다시 말해 상태 전이는 과거의 정보, 즉 지금까지 어떤 상태들을 거쳐 왔고 어떤 행동들을 취해 왔는지는 일절 신경쓰지 않는다.
이처럼 현재의 정보만 고려하는 성질을 마르코프 성질(markov property) 이라 한다.
마르코프 성질을 도입하는 가장 큰 이유는 '문제를 더 쉽게 풀기 위해서'이다.
만약 마르코프 성질을 따른다고 가정하지 않는다면 과거의 모든 상태와 행동까지 고려해야 해서, 그 조합이 기하급수적으로 많아진다.(진짜 기하급수적이다.)
보상 함수
두 번째로 보상에 대해 생각해보자.
설명이 복잡해지지 않도록 보상은 '결정적'으로 주어진다고 가정하겠다.
에이전트가 상태 s에서 행동 a를 수행하여 다음 상태 s'가 되었을 때 얻는 보상을 r(s, a, s')라는 함수로 정의한다.
예시를 위해 아래 그림을 보상 함수로 정의해보자.


- 상태 s=L2에서
- 행동 a=Left를 수행하여
- 다음 상태 s'=L1 으로 전이되었을 때,
- 보상 r=1 을 제공받게 된다.
참고로 위 예에서는 다음 상태 s'만 알면 보상이 결정되기 때문에, 아래와 같이 표현해버릴 수도 있다.
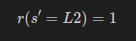
참고로 보상이 '확률적'으로 주어질 수도 있다.
예를 들어 어떤 장소에 가면 0.8의 확률로 적에게 습격 당에 -10의 보상을 얻는 경우이다.
물론 보상 함수 r이 '보상의 기댓값'을 반환하도록 설정하면, 이후 이어지는 MDP이론은 보상이 결정적일 때와 다름없이 성립한다.
이번 장에서는 보상이 결정적으로 주어진다고 가정하고 이야기하자.
에이전트의 정책(Policy)
마지막으로 에이전트의 정책에 대해 생각해보자.
정책에서 중요한 점은 에이전트는 '현재 상태'만으로 행동을 결정할 수 있다는 것이다.
환경의 상태 전이에서는 현재 상태 s와 행동 a만을 고려하여 다음 상태 s'를 결정할 수 있다.
'현재 상태'만으로 충분한 이유는 '마르코프 성질'의 특성에 있다.
사실 마르코프 성질은 에이전트가 아닌 '환경'에 제약을 거는 것이고, 표현력에 한계가 있음을 반증하는 것이다.
그 대신, 정책을 설계하는 데에 있어서 유리함을 가져오는 트레이드오프를 얻는 것이다.
마르코프 성질을 적용할 수 있는 상황(환경)이라면 적극적으로 마르코프 성질을 도입하는 것이 문제 풀이에 유리해진다는 의미이기도 하다.
정책 또한 두가지로 분류할 수 있다.
결정적 정책

에이전트는 특정한 상태에서 반드시 특정한 결정을 내린다.
이를 '결정적 정책'이라고 한다.
결정적이므로 함수로 정의할 수 있고, 이를 수식으로 표현하면 아래와 같다.

함수 mu는 s 상태에서 행동 a를 반환하는 함수이다.
이 예에서는 이렇게 작성할 수 있다.

확률적 정책

에이전트는 특정한 상태에서 특정한 행동을 할 확률을 갖는 정책도 설계가 가능하다.
이렇게 에이전트의 행동이 확률적으로 결정되는 정책은 수식으로 다음과 같이 표현할 수 있다.

이 수식은 상태 s에서 행동 a를 취할 확률을 나타낸다.
위 그림을 수식으로 나타내면 이렇게 표현할 수 있을 것이다.

드디어 이 세가지를 수식으로 표현했다.
- 상태 전이(f,p): 상태는 어떻게 전이되는가?
- 보상(r): 보상은 어떻게 주어지는가?
- 정책(pi, mu): 에이전트는 행동을 어떻게 결정하는가?
이제 이를 이용해 MDP의 목표를 정의하자.
MDP의 목표
MDP의 목표는 최적 정책(Optimal Policy)을 찾는 것이다.
여기서 최적 정책이란, 수익이 최대가 되는 정책이다.
이 최적 정책을 수식으로 정확하게 표현해보고자 한다.
그 전에 이걸 먼저 알고, 본격적으로 수식으로 표현해보자.
- 일회성 과제
- 지속성 과제
- 수익
- 할인율
일회성 과제와 지속성 과제
MDP는 문제에 따라 일회성 과제와 지속성 과제로 나뉜다.
- 일회성 과제
- '끝'이 있는 문제
- 바둑은 일회성 과제이다.(승패가 결정된다.)
- 매번 아무것도 없는 초기 상태로 시작한다.
- 시작부터 끝까지의 일련의 시도를 에피소드(episode)라 한다.
- 지속적 과제
- '끝'이 없는 문제
- 재고 관리는 끝이 없는 과제이다.(회사가 망하지 않는 한)
- 판매량과 재고량을 보고 최적의 구매량을 결정해야 한다.
수익(G)
그 다음으로 새로운 용어인 '수익'(return)을 알아보자.
이 수익을 극대화하는 것이 에이전트의 목표이다.
시간 t에서의 수익 G_t는 아래와 같이 정의된다.

여기서 다음과 같은 사실에 주목할 수 있다.
- 현재 얻는 수익 G_t는 현재 얻는 보상 R_t 뿐만 아니라, 미래에 얻을 보상 R_t+1에도 영향을 받는다.
- 미래에 얻는 보상 R_t+x는 시간이 갈수록 할인율(감마)가 점점 곱해져 간다.
할인율이 있는 것이 의아할 수 있는데, 이는 지속적 과제에서 수익이 무한대가 되지 않도록 방지하기 위해서이다.
할인율이 없다면, 즉 r=1이라면 지속적 과제에서 수익이 무한대까지 늘어나게 된다.
또한 할인율은 가까운 미래의 보상을 더 중요하게 보이도록 만들어, 현실 세계의 행동원리를 반영하기 좋다.
화폐 가치는 인플레이션에 의해 갈수록 떨어지게 되어 있다.
상태 가치 함수
방금 정의한 '수익'을 극대화하는 것이 에이전트의 목표라고 했다.
여기서 주의할 점이 하나 있다.
에이전트와 환경이 '확률적'으로 동작할 수 있다는 점이다.
- 에이전트는 다음 행동을 확률적으로 결정할 수 있다.
- 상태 역시 확률적으로 전이될 수 있다.
- 따라서 얻는 수익 역시 '확률적'으로 달라질 것이다.
즉, 비록 같은 상태에서 시작하더라도 수익이 에피소드마다 '확률적'으로 달라질 수 있다.
이러한 확률의 동작에 대응하기 위해서는 기댓값, 즉 '수익의 기댓값'을 지표로 삼아야 한다.
상태 S_t가 s이고(시간 t는 임의의 값), 에이전트의 정책이 pi일 때, 에이전트가 얻을 수 있는 기대 수익을 다음처럼 표현할 수 있다.

여기서 정의한 v_pi를 상태 가치 함수라 한다.
위 식의 우변에서 에이전트의 정책 pi는 조건으로 주어진다.
정책이 바뀌면 에이전트가 얻는 보상도 바뀌고 총합인 수익도 바뀌기 때문이다.
이런 특성을 명시하기 위해 상태 가치 함수는 v_pi처럼 pi를 v의 밑으로 쓰는 방식을 많이 따른다.
또한 위 식을 아래 식처럼 쓰기도 한다.

최적 정책과 최적 가치 함수
강화 학습의 목표는 최적 정책을 찾는 것이다.
그렇다면 이 '최적'은 어떻게 표현이 가능한걸까?
먼저 두가지 정책 pi1와 pi2가 있다고 가정해보자.

만약 이러한 경우에는 두 정책의 우열을 가릴 수 없을 것이다.
그러면 어떠할 때 두 정책의 우열을 가릴 수 있을까?

이러한 경우에는 pi1 >= pi2 라 pi1이 더 나은 정책이라고 할 수 있다.
이렇게 두 정책의 비교를 하게 됨으로써, 두 정책의 '우열'을 가릴 수 있게 되었다.
그렇게 구한 최적 정책은 pi_*로 표현한다.

그리고 이 최적 정책의 상태 가치 함수를 최적 상태 가치 함수라 하며, 기호로 v_*로 표현한다.
MDP 예제
이번 절에서는 MDP에 속하는 구체적인 문제 하나를 정의해보자.

- 에이전트는 오른쪽이나 왼쪽으로 이동할 수 있다.
- 상태 전이는 결정적이다.
- 에이전트가 L1에서 L2로 이동하면 사과를 받아 +1의 보상을 얻는다.
- 에이전트가 L2에서 L1으로 이동하면 사과가 다시 생성된다.
- 벽에 부딪히면 -1의 보상을 얻는다. 즉, 벌을 받는다.
- 지속적 과제, 즉 '끝이 없는' 문제다.
최적 정책 찾기
두 칸짜리 그리드 월드에서의 최적 정책은 무엇일까?
이번에는 상태와 행동이 각 2개씩이므로 정책의 개수를 모두 나타낼 수 있다.
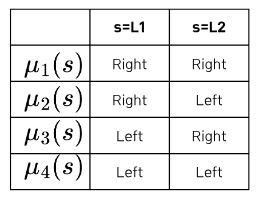
그림의 네가지 정책 중 최적 정책이 존재한다!
그럼 각 정책의 상태 가치 함수를 계산해보자.
현재 환경의 상태 전이와 정책이 모두 결정적이기 때문에 간단하게 구할 수 있다.
할인율을 0.9로 가정하고 계산해보겠다.
먼저 mu_1일때의 L1이다.
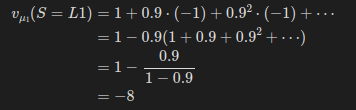
여기서 0.9의 곱의 합은 무한등비급수의 합 공식을 이용했다.
그 다음은 정책이 mu_1일 때 상태 L2에서의 상태 가치 함수이다.
이제부턴 그냥 코드로 근사해서 풀자.


대략 10 정도가 나온것을 확인할 수 있었다.
이제 이 각 값들을 표로 채워보자.

표를 보면 정책 mu_2가 모든 상태에서 다른 정책들보다 상태 가치 함수의 합이 더 크다.
따라서 정책 mu_2가 바로 우리가 찾는 최적 정책이다.
이렇게 우리는 MDP의 목표를 달성했다.
정리
이번 장에서 배운 내용들을 키워드로 정리해보자.
- MDP
- 결정적
- 확률적
- 마르코프 성질
- MDP의 표현
- 상태 전이(f, p)
- 보상(r)
- 정책(pi, mu)
- 일회성 과제
- 지속적 과제
- 수익(G)
- 할인율(gamma)
- MDP의 가치 함수
- 상태 가치 함수(V_pi, v_pi)
- 최적 가치 함수(v_*)
- 상태 가치 함수(V_pi, v_pi)
- 최적 정책(pi_*)
'AI Repository > 기초 강화학습' 카테고리의 다른 글
| [강화학습] Off-Policy, On-Policy, 중요도 샘플링 (0) | 2025.08.31 |
|---|---|
| [강화학습] 벨만 방정식 (0) | 2025.08.29 |
| [강화학습] 밴디트 문제 (0) | 2025.08.28 |
| Define-by-Run과 Define-and-Run (0) | 2025.08.25 |
| python - from A import B와 import A.B as b의 차이 (0) | 2025.08.25 |