최적 정책은 '평가'와 '개선'을 번갈아 반복하여 얻는다.
'평가' 단계에서는 정책을 평가하여 가치 함수를 얻는다.
그리고 '개선' 단계에서는 가치 함수를 탐욕화하여 정책을 개선한다.
이 두 과정을 번갈아 반복함으로써 최적 정책(과 최적 가치 함수)에 점점 다가갈 수 있다.
신경망에 비유하자면, 강화학습의 '평가'는 손실 함수 역할이고, 강화학습의 '개선'은 경사 하강법이 수행하는 역할이다.
예를 들어 몬테 카를로 방법으로 강화학습을 수행한다고 해보자.
pi라는 정책이 있다면, 몬테 카를로 법을 이용해 V_pi를 얻을 수 있다.
그다음은 개선 단계이다. 개선 단계에서는 탐욕화를 수행하며, 다음 수식으로 표현할 수 있다.
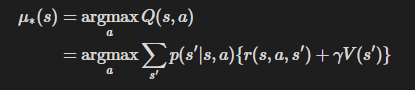
계산 단계에서는 가치 함수의 값을 최대로 만드는 행동을 선택한다.
이를 탐욕화라고 한다.
Q 함수의 경우 위 식과 같이 Q 함수가 최댓값을 반환하는 행동을 선택한다.
이때 행동이 s 단 하나로 결정되므로 함수 mu(s)로 나타낼 수 있다.
또한 위 식의 아랫부분처럼 상태 가치 함수 V로도 나타낼 수 있다.
만약 가치 함수 V를 사용하며 정책을 개선한다면 식의 아랫 부분을 계산하면 될 것이다.
그런데 이 식에는 제약이 있다.
일반적인 강화학습 문제에서는 환경 모델, 즉 p와 r을 알 수 없다.
따라서 강화학습 모델에서는 위 식의 Q 함수로 구현된 부분을 사용해야 한다.
결국 Q 함수를 대상으로 개선할 경우 Q 함수를 '평가'해야 한다.
상태 가치 함수와 행동 가치 함수를 평가하는 방식을 비교해보자.
상태 가치 함수 평가
- 일반적인 방식
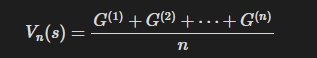
- 증분 방식

Q 함수 평가
- 일반적인 방식

- 증분 방식
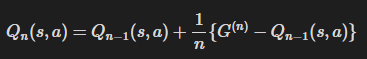
이와 같이, Q 함수를 사용하던 상태가치 함수를 사용하던 평가와 개선이라는 과정을 거치는 것에는 변함이 없다.
'AI Repository > 기초 강화학습' 카테고리의 다른 글
| [강화학습] 에이전트 구현 방법 - 분포 모델과 샘플 모델 (0) | 2025.09.01 |
|---|---|
| [강화학습] 시간차 학습(TD), SARSA, Q-Learning (0) | 2025.09.01 |
| [강화학습] Off-Policy, On-Policy, 중요도 샘플링 (0) | 2025.08.31 |
| [강화학습] 벨만 방정식 (0) | 2025.08.29 |
| [강화학습] 마르코프 결정 과정(MDP) (0) | 2025.08.28 |