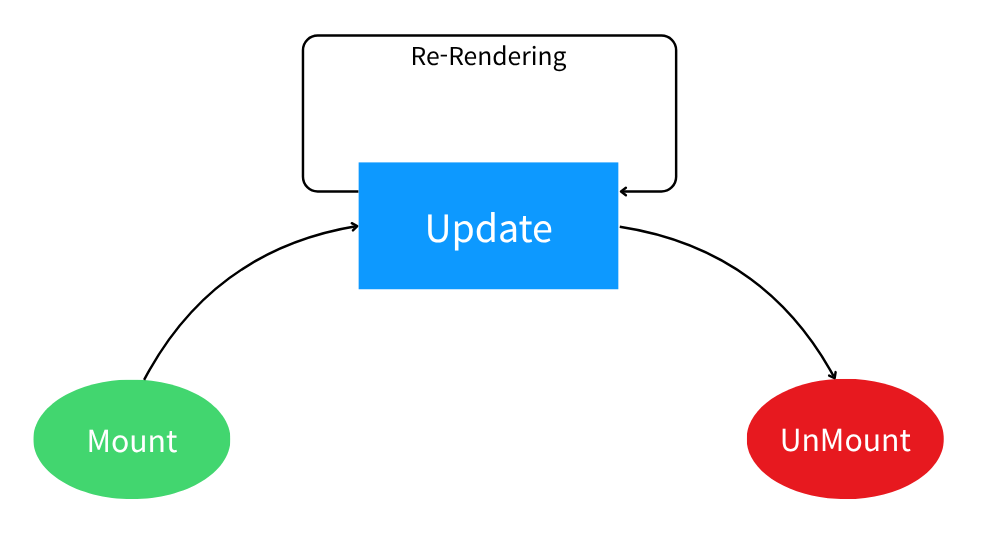
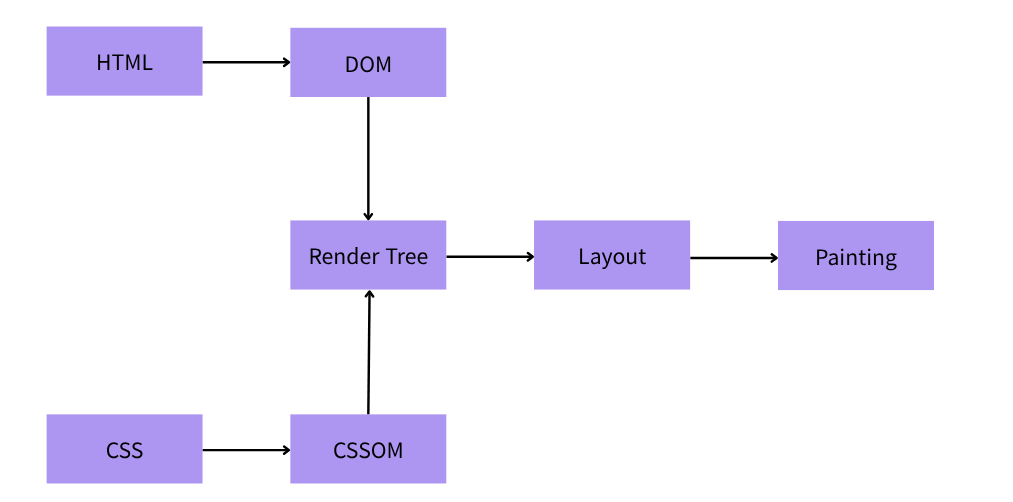
지금 할 수 있으면 해라.지금 할 수 없으면 하지마라.지금 해야하면 해라.이번주에 한 것항암치료 보조릿코드 Hard 1일 1문제 - 스트릭 기록하기리액트 기본 구조 & API 학습결국 API류는 직접 쓰고 트레이드오프를 고민해봐야 능숙해진다.리액트 튜토리얼카페 알바 이번주에 하지 못한 것코틀린 코루틴 학습쿠팡커피 원두 종류 및 맛 분석(블렌딩 or 싱글오리진)USACO Gold - DP 번역 및 문제풀이큰 의미가 없는 듯.핀잇 기능 요구사항 도출 & 백엔드 설계파드셉 분석다음주에 할 수 있는 것핀잇 프로젝트 분석기본 UI 컴포넌트 구성기능 요구사항(유스케이스) 도출요구사항에 따른 UI 컴포넌트 완성요구사항에 따른 백엔드 도메인 모델 설계요구사항에 따른 계약 완성(가능하면) UI 컴포넌트/도메인 모델 코드..