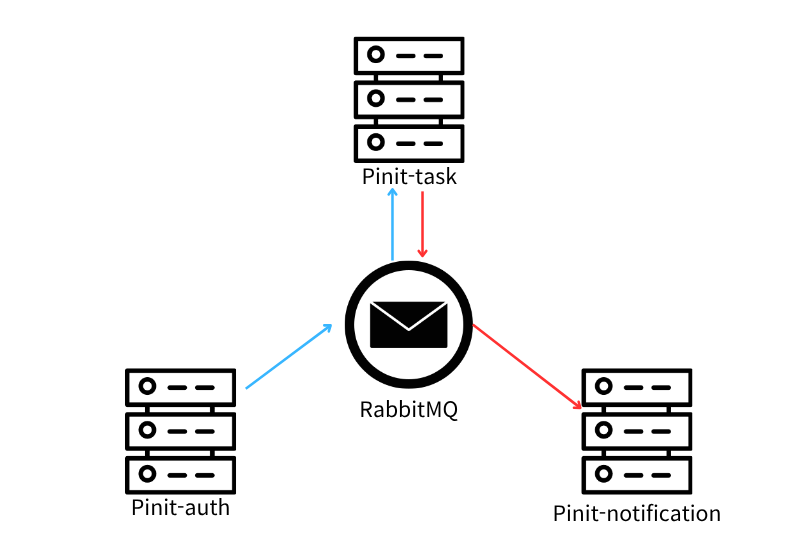
서비스를 배포할 때, 롤링/카나리/블루 그린같은 무중단 배포 전략을 고려하다 보면, 자연스레 컨테이너를 다루는 방식으로 손이 가게 된다. 현재 진행하고 있는 프로젝트 Pinit의 경우, MSA로 구성되어 있어서, 무중단 배포를 위한 전략을 쉽게 선택할 수 있는 도구가 필요했다. 이때, 도커 컴포즈와 쿠버네티스를 보통 이야기하는데, 이번 기회에 쿠버네티스를 한번 쭉 써보면서 MSA의 인프라 구성에 대해 이해하고자 다음과 같이 튜토리얼을 시작했다. k3s는 Rancher사가 배포한 경량 Kubernetes로, 리소스가 적은 환경이나 로컬 실습에 적합하다.k3s는 설치가 매우 간단하며, 단일 바이너리에 Kubernetes의 핵심 기능을 모두 포함하고 있다.이 섹션에서는 Ubuntu 20.04+ 환경에 k3..