본 글은 강화학습과 신경망에 대한 기초적인 지식(벨만 방정식, Q-Learning, 퍼셉트론, FNN, CNN, RNN, etc.)이 있다고 가정하고 작성되었습니다.
또한, 본 글은 DQN/정책 정사법과 관련된 내용을을 다루지는 않으니 주의해주시기 바랍니다.
신경망을 위한 전처리
신경망에서 '범주형 데이터'를 다룰 때에는 원-핫 벡터로 변화나는 것이 일반적이다.
- 범주형 데이터: 범주로 묶을 수 있는 것. 혈액형이나 옷 사이즈 등
- 원-핫 벡터: 한 개의 원소만 1이고 나머지는 모두 0인 벡터
예를 들자면, 혈액형 A/B/AB/O 를 각각 (1,0,0,0)/(0,1,0,0)/(0,0,1,0)/(0,0,0,1)로 치환하는 것이다.
그럼 아래와 같은 문제는 어떻게 원-핫 벡터로 바꿀 수 있을까?

3x4 크기의 셀을 각각 범주로 보면, 이 데이터 또한 '범주형 데이터'로 볼 수 있다.
따라서 이 데이터를 전처리의 일환으로 원-핫 벡터로 바꾸는 작업을 코드로 수행해보자.

여기서 vec[np.newaxis, :] 의 경우, 배치 처리를위해 새로운 축을 추가한 형태이다.
Q 함수를 표현하는 신경망
Q 함수는 단독으로 사용 시 테이블(딕셔너리)로 구현한다.
예를 들어, 다음과 같이 코드를 작성한다.

강화학습에 신경망을 적용할 땐, Q 함수 자체를 신경망으로 '변신'시킨다.
크게 다음과 같은 구조를 생각해볼 수 있을 것이다.
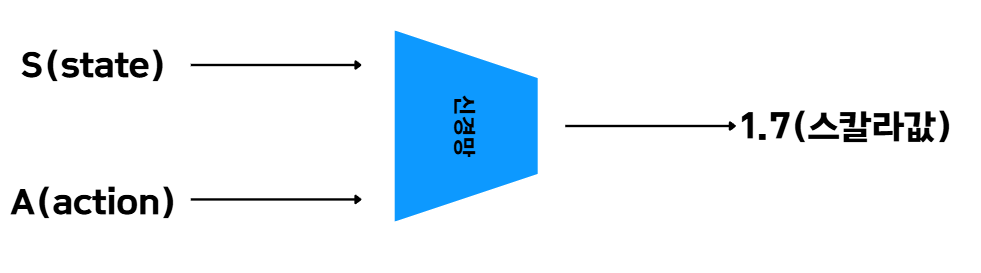

첫 번째 구조는 상태와 행동 두 가지를 입력으로 받는 신경망이다.
출력으로는 Q 함수의 값을 하나만 내보낸다.
(일단 배치는 고려하지 말아보자.)
두 번째 구조는 상태만을 입력받아, 가능한 행동의 개수만큼 Q 함수의 값을 출력하는 신경망이다.
예를 들어 행동의 가짓수가 4개라면 원소 4개짜리 벡터를 출력한다.
그런데 첫 번째 방식에는 큰 문제가 하나 있다.
이걸 계산하기가 까다롭다.
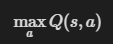
따라서 두번째 기법을 사용하도록 하자.
2계층의 완전 연결 형태로 구성된 신경망으로 구현하겠다.

이로써 Q 함수를 신경망으로 대체할 수 있게 되었다.
계속해서 방금 작성한 신경망을 이용하여 Q 러닝 알고리즘을 구현해보자.
신경망과 Q Learning
먼저 Q 러닝에 대해 가볍게 복습해보자.
Q러닝은 다음 식을 통해 Q 함수를 갱신한다.

이 식에 의해 Q 함수는 Target을 향해 갱신된다.
이때 alpha는 목표 방향으로 얼마나 나아갈 것인지 조정한다.
이때, Target을 T로 간소화해보자.
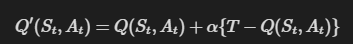
위 식은 입력이 S, A일 때 출력이 T가 되도록 Q 함수를 갱신하는 것으로 해석할 수 있다.
신경망 맥락에 대입하여 표현하자면, 입력이 S, A일 때 출력이 T가 되도록 학습시킨다는 뜻이다.
즉, T를 정답 레이블로 볼 수 있다.
또한, T는 스칼라값이기 때문에 회귀 문제로 생각할 수 있다.
이상을 바탕으로 Q 러닝을 수행하는 에이전트를 구현해보자.

학습 코드는 다음과 같다.
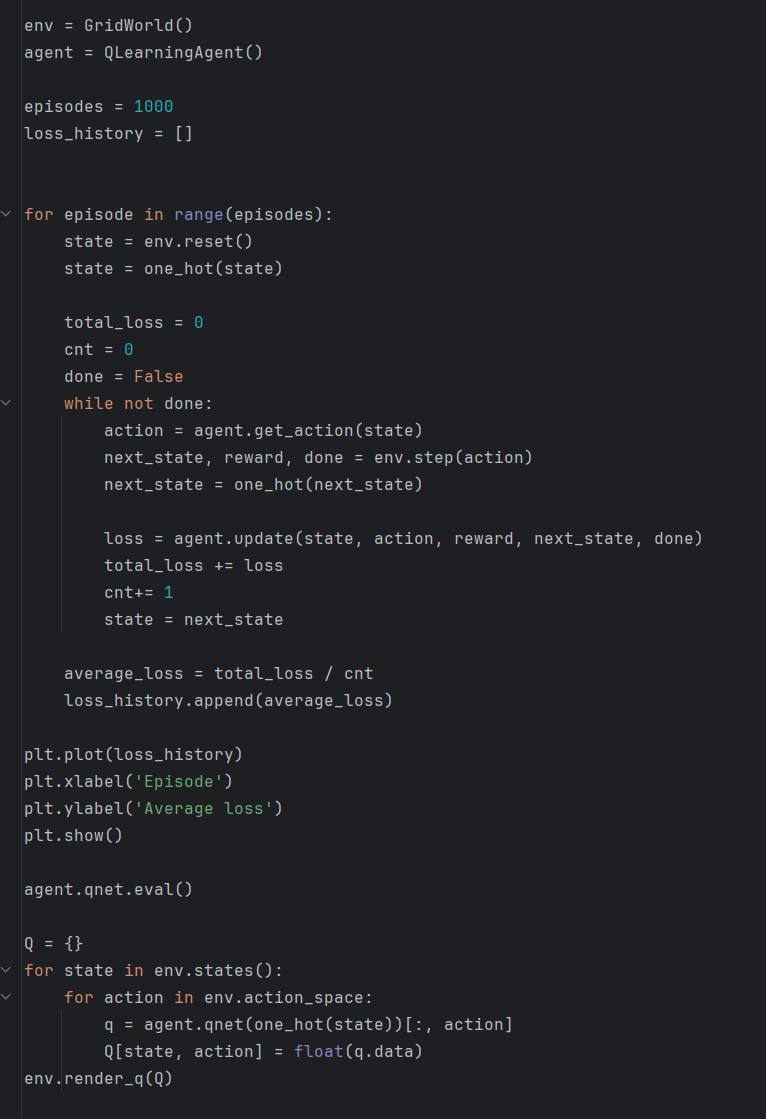
본 내용은 밑바닥부터 시작하는 딥러닝 4를 참고하여 작성되었습니다.
밑바닥부터 시작하는 딥러닝 4 - 예스24
『밑바닥부터 시작하는 딥러닝』 시리즈, 이번엔 강화 학습이다! 강화 학습 핵심 이론부터 문제 풀이, 심층 강화 학습까지 한 권에!이 책의 특징은 제목 그대로 ‘밑바닥부터 만들어가는 것’이
www.yes24.com
'AI Repository > 기초 강화학습' 카테고리의 다른 글
| [강화학습] Experience Replay, ER - Catastrophic Forgetting의 해소 (0) | 2025.09.12 |
|---|---|
| [강화학습] DQN (0) | 2025.09.12 |
| [강화학습] 에이전트 구현 방법 - 분포 모델과 샘플 모델 (0) | 2025.09.01 |
| [강화학습] 시간차 학습(TD), SARSA, Q-Learning (0) | 2025.09.01 |
| [강화학습] 강화학습에서 최적 정책을 찾는 방법 (0) | 2025.09.01 |