비동기(Promise, Async, Coroutine, Reactor) 에 대한 깊은 이해를 수행하다보면, 필연적으로 마주치는 어려움이 있다.
바로 이벤트 루프 모델은 어떻게 DB I/O 방식을 바꾸는가 이다.
상당히 이해하기 어려운 개념이기 때문에, 읽는 독자 여러분들도 직접 그림을 그려보며 이해하는 것을 권장한다.
자바+스프링의 예시를 바탕으로 이야기를 전개해 나가겠다.
목차
- 이벤트 루프(비동기) 모델의 목표
- DB 드라이버와 DB간의 통신 방식
- DB 드라이버와 애플리케이션 간에 발생하는 문제점
- 결론
1. 이벤트 루프(비동기) 모델의 목표
일반적인 HTTP 요청의 처리 흐름을 그려보면 다음과 같다.

- 속이 빈 형태 - 인터페이스
- 속이 채워져있는 형태 - 구현체
너무나 당연한 이야기지만, 애플리케이션 코드 플로우는 자체적인 context를 계속 유지하는 것이 아닌, 사용자의 요청에 trigger되어 생성되었다가 소멸된다.
결국 애플리케이션 코드의 실행 권한을 만드는 곳은 웹 계층이 결정한다.
웹 계층이 스레드 모델로 되어있는가/이벤트 루프 모델로 되어있는가에 따라 결과가 달라지는 것이다.

하지만, 스레드 모델에는 "스레드 자체의 무거움"과 "블로킹"이라는 문제가 겹쳐, 해결하기 어려운 문제를 만든다.
블로킹은 “스레드”라는 유한 자원을 붙잡는다
기본적으로 스레드는 굉장히 무거운 자원이다.
- 요청 1개를 처리하는 동안 스레드 1개를 할당하는 구조에서,
- DB 호출/외부 HTTP/파일 I/O 등으로 스레드가 블로킹되면 그 스레드는 그 시간 동안 유용한 일을 못 하면서도 계속 점유된다.
- 동시 요청이 늘면 “대기 중인 스레드”가 급격히 늘고, 결국 가용 스레드 풀 고갈이 발생한다.
그 결과, 새 요청은 스레드를 못 받아 큐잉(대기열 증가) → 응답 지연 증가 → 타임아웃으로 전파된다.
스레드를 늘려도 해결이 제한적인 이유
“그럼 스레드를 더 늘리면 되지 않나?”가 자연스러운 대응인데, 명백한 한계가 있다.
1) 메모리 비용
- JVM 스레드는 보통 스택 메모리 등으로 스레드 수가 늘수록 메모리 사용량이 선형 증가한다.
- 스레드가 수천 단위로 늘면 메모리 압박, GC 압박이 커지게 된다.
2) 스케줄링/컨텍스트 스위칭/캐시 페널티
- runnable 스레드가 많아지면 스케줄링 부담이 커지고, 컨텍스트 스위칭과 캐시 미스가 늘어 처리량이 오히려 떨어지는 구간이 생긴다.
3) 보통 “진짜 병목”은 외부 시스템이다
DB/외부 API가 느려서 블로킹이 길어지는 경우, 스레드를 늘리면 애플리케이션은 더 많은 동시 호출을 만들고, 외부 시스템의 큐/락/커넥션이 터지면서 전체 지연이 더 악화될 수 있다.
여기서 이벤트 루프 모델은 다음을 주장한다.
- 커널 스레드는 너무 무겁고 무한히 늘릴 수 없다.
- 따라서 각 작업이 스레드 하나를 전부 사용하는 대신, 직접 만든 "비동기 I/O + 인터리빙"을 사용해서 "선점형 스레드 스케줄링"이 아닌, "협력형 스레드 스케줄링"을 구현한다.
참고) Coroutine은 그럼 뭐하는 녀석이지?
지금까지 이벤트 루프에 대한 설명은 비동기 I/O + 인터리빙 관점에 대해서만 설명됐다.
코루틴은 여기서 한술 더 떠, 코드 작성자가 실행 흐름을 직접 중단(suspend)·재개(resume)할 수 있게 만들어, 특정 지점(await, yield 등)에서 제어권을 양보할 수 있게 한다.
또한, 이때의 실행을 다른 작업으로 넘기는 과정에서 저장/복원해야 하는 상태가 더 적고, 커널 스케줄러 개입이 없거나 적어서 비용이 낮은 경우가 많다.

2. DB 드라이버(WAS side)와 MySQL(DB side)간의 통신 방식

간단하게 트랜잭션 스크립트 패턴으로 송금 로직을 작성해보자.
@Service
public class AccountService{
@Autowired
private AccountRepository accountRepository;
@Transactional
public void transfer(Long sender, Long receiver, int amount){
Account senderAccount = accountRepository.findById(sender);
Account receiverAccount = accountRepository.findById(receiver);
senderAccount.withdraw(amount);
receiverAccount.deposit(amount);
}
}이 경우, JPA가 이를 적절한 JDBC SQL 쿼리로 바꾸고, JDBC는 이를 아래의 SQL로 바꿀 것이다.
START TRANSACTION;
UPDATE account
SET balance = balance - 10000
WHERE account_id = 1;
UPDATE account
SET balance = balance + 10000
WHERE account_id = 2;
COMMIT;이때, DB 커넥션을 이용해 해당 SQL을 전송하게 되고, 이는 MySQL 서버에 존재하는 (커넥션에 1:1 대응되는) 스레드의 세션 관리 방식을 통해 해당 트랜잭션의 격리성을 보장하는 것이다.
그래서, 해당 DB 커넥션을 다른 스레드가 공유해서 사용하게 되면 격리성이 깨지는 문제가 발생한다.
3. DB 드라이버와 이벤트 루프 애플리케이션 간에 발생하는 문제점
R2DBC(Reactive Relational Database Connectivity)는 어떻게 트랜잭션을 열고 닫는가?
우선 간단하게, 리액티브 모델을 사용한다고 가정하고, 이벤트 루프가 만능이라 다음과 같이 트랜잭션을 자유자재로 처리할 수 있다고 생각해보자.
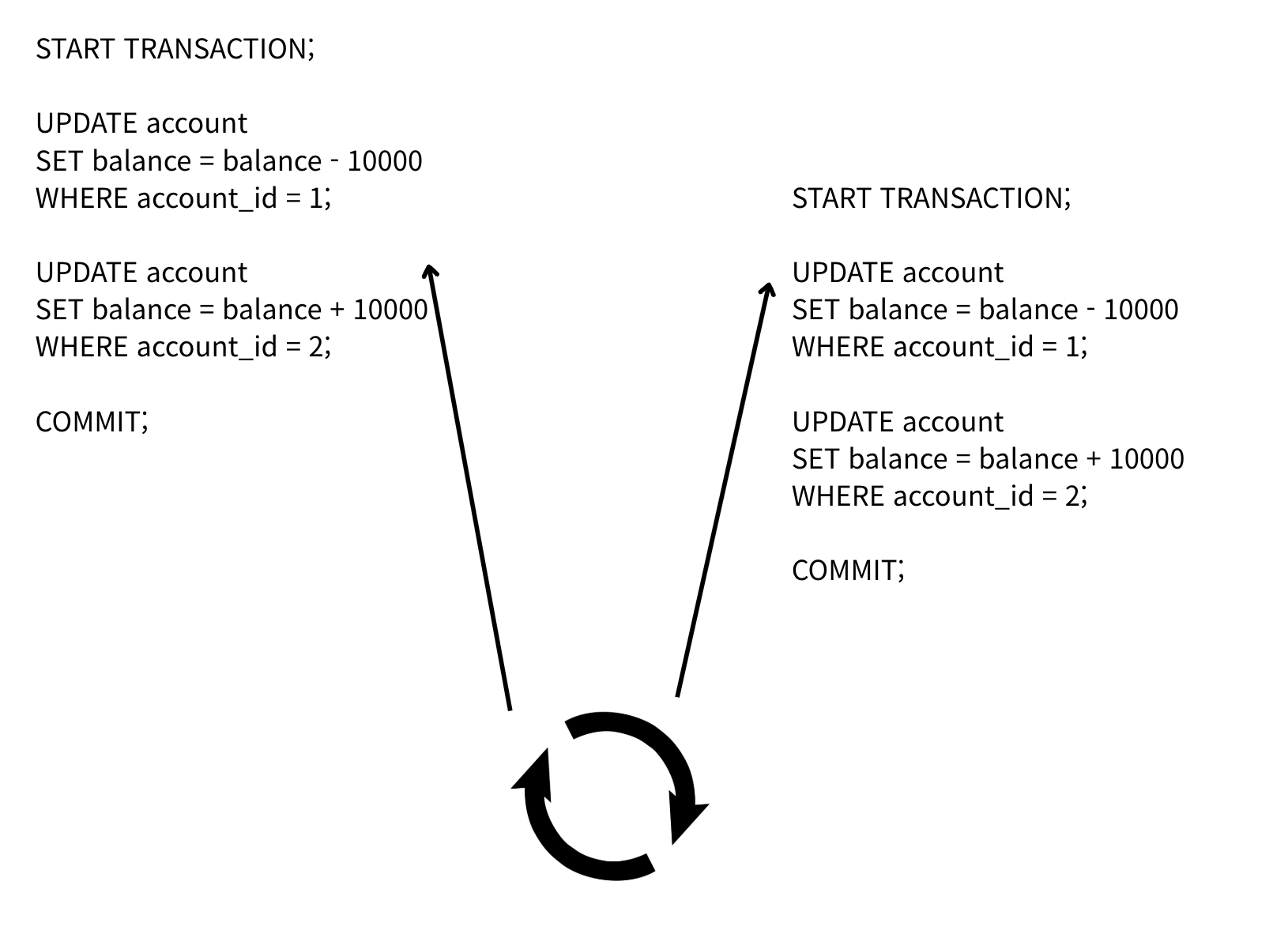
트랜잭션은 START TRANSACTION 선언 후, 최종적으로 transaction commit을 수행해야 한다.
하지만, 지금 상상한 상황에서는 해당 비즈니스 로직이 트랜잭션 세션을 명시적으로 갖지 못한다.
완전한 이벤트 루프(상상한 개념)로는,
- 한 커넥션에서 리액티브 컨텍스트 1이 트랜잭션을 열고,
- 다른 리액티브 컨텍스트 2가 또 트랜잭션을 여는 걸 생각했는데,
이러면 커넥션 세션은 하나의 트랜잭션 세션만 가질 수 있으니, 두 개의 리액티브 컨텍스트가 트랜잭션 세션을 공유해, ACID의 격리성이 깨지는 문제가 발생한다.
그래서, 트랜잭션은 구독 시점에 시작한다(reactive는 “deferred”).
Spring의 트랜잭션 인터셉터가 리턴된 reactive 타입을 데코레이션하고, 실제 트랜잭션 시작/정리는 subscription에 의해 활성화된다.
그리고, 이때 커넥션의 소유권은 하나의 컨텍스트만 소유 가능하다.
간단한 예시로, 트랜잭션 컨텍스트는 다음과 같은 상태 전이 모델을 갖는다.

결국 이 상태를 저장할 컨텍스트가 존재해야 한다.
이 트랜잭션 컨텍스트가 서로 간섭하게 되면, ACID 중 하나인 격리성이 깨지게 된다.
그래서 이때 커넥션의 소유권은 하나의 컨텍스트만 소유 가능하다.
R2DBC는 커넥션이 생길 때마다, 해당 리액티브 컨텍스트에 DB 커넥션을 "흘려보냄"으로써 트랜잭션을 사용 가능하게 한다.
R2DBC의 목적은 보통 DB 디스크 I/O를 이벤트 루프로 바꾸는 것이 아니라, 애플리케이션 계층에서 DB를 향한 네트워크 I/O 대기 동안 스레드를 점유하지 않는 클라이언트 모델을 제공하는 데 있다.

결국, 리액티브(비동기) 모델도 커넥션을 얻기 위해 대기하고 있는 로직이 생기기 마련이다.
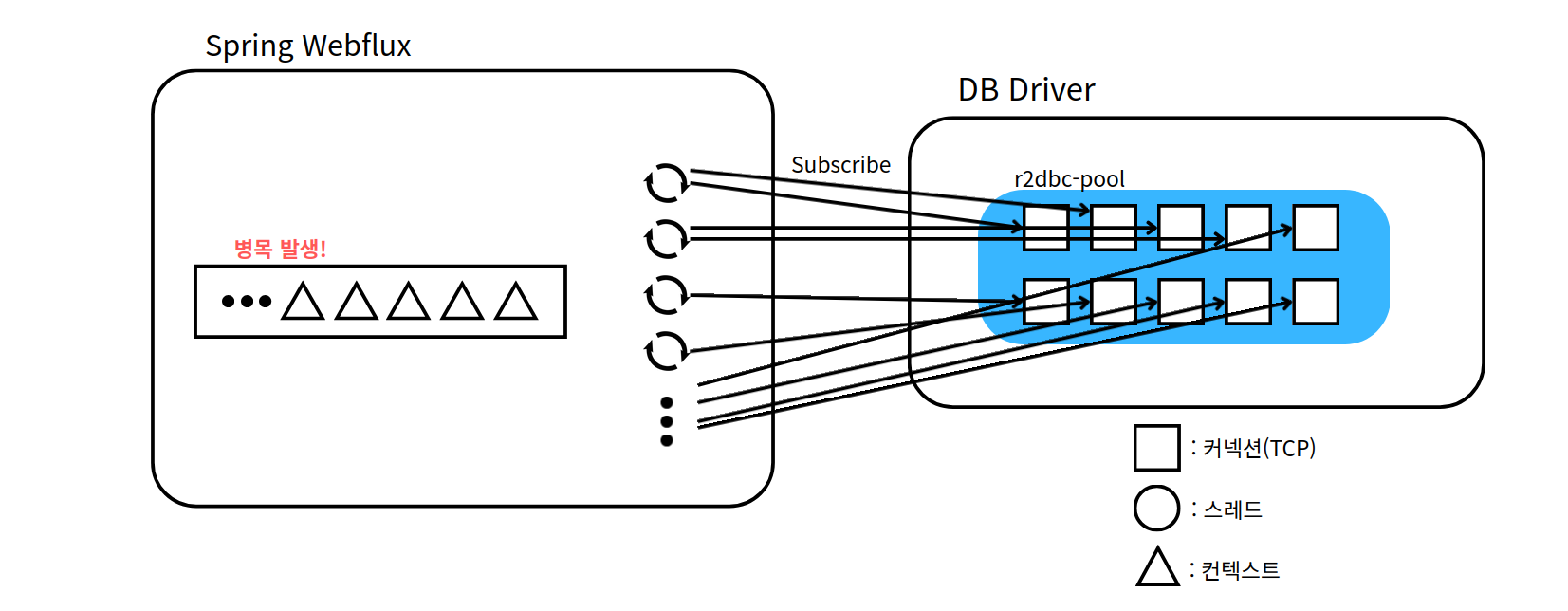
다만, 이때는 커다란 스레드 단위가 대기하는 것이 아닌, 작은 "컨텍스트"가 대기하는 것이기 때문에 리소스를 좀 더 적게 소모할 수 있는 것이다.
그럼 다음과 같은 의문이 생길 수 있다.
"근데 그럼 이벤트 루프 모델의 블로킹되지 않는다는 장점이 사라지는 거 아닌가? 결국 구독 시점부터 DB I/O가 끝날때까지 기다려야 하는거잖아."
그럼 이벤트 루프 모델도 DB 커넥션을 늘리면 되는 것 아닌가?
이러한 접근 방식을 선택하는 건 스레드 풀의 접근 방식과 큰 차이가 없는 방식이다.
DB 커넥션은 HikariCP 기준 기본값 10개로 설정되는데, 이 커넥션을 30개로 늘렸다고 생각해보자.
하나의 WAS가 혼자서 많이 점유하는 순간, DB에 내장되어 있는 기본 150개의 커넥션을 다 써버리는 문제가 발생할 수 있고, 그 결과 다른 WAS가 DB 커넥션을 얻지 못할 수 있다.

그럼 DB쪽 커넥션을 많이 늘리면 안되나?
라는 생각이 들 수 있고, 실제로 어느정도는 타당하다.
실제로 DB 커넥션 풀은 성능 튜닝 시 자주 언급되는 주제기도 한데, 스레드가 많아지면 많아질수록 컨텍스트 스위칭에 발생하는 비용이 커지기 때문에, Thrashing과 같은 좋지 않은 결과를 맞이할 수도 있다.
즉, 이 해결책도 모든 상황에 어울리는 만능 해결책은 아니다.
결국 핵심은 오래 걸리는 Disk I/O니, 그럼 DB가 관리하는 커넥션도 이벤트 루프 모델로 바꾸면 안될까?
라는 생각이 들 수 있다.

하지만 DB 입장에서, 트랜잭션의 처리 과정 자체가 커널/CPU 리소스를 소모하는 작업이고, 이벤트 루프로 바꿀 이유가 없다.
- DB의 트랜잭션 연산은 ACID/MVCC 작업을 위해 Undo Log / Redo Log를 메모리에 작성하며, 이 자체가 CPU 자원을 많이 소모한다.
- NVMe로 넘어가게 되면서, 장치가 빠를수록 “디스크가 느려서 기다리는” 대신 “CPU가 처리량 한계”가 되는 케이스가 많아졌다.
- 따라서, 위와 같은 컨텍스트를 굳이 리액티브 모델로 바꾸지 않아도, 성능 상으로는 큰 차이가 없다.
그래서 Disk -DBMS 간의 File I/O에는 전통적인 스레드 모델이 유지되고 있다.
4. 결론
이쯤에서 문제를 정리할 수 있다.
- 스레드가 블로킹되지는 않는다. 즉, 스레드가 아무것도 안하고 가만히 있지는 않게 된다.
- 하지만, 각 요청들이 커넥션 세션을 얻기 위해 기다리는 상황은 발생할 수 있다.
이벤트 루프 모델은 DB가 병목인 상황에서 처리량을 자동으로 개선하는 해법이 아니다.
근본적으로 DB는 ACID를 보장하려다 보니, 필히 특정 세션에 묶이고 해당 세션을 얻기 위해 기다리게 되는 문제가 발생하기 때문이다.
둘 다 DB의 응답을 받기까지 특정 로직이 대기해야 함은 변함이 없다.
단, 이벤트 루프 모델의 경우 DB의 ACID가 필요하지 않은 다른 요청들이 있을 때, 해당 요청들은 "DB 커넥션을 얻기 위한 대기 큐"에 들어가지 않고 즉시 응답받을 수 있으므로, 성능 상의 유리함을 가져갈 수 있는 것이다.
'Article - 깊게 탐구하기 > 트랜잭션 완전정복' 카테고리의 다른 글
| [트랜잭션 완전정복] 2편 - 트랜잭션 고립 수준(트랜잭션 격리 수준, Transaction Isolation Level) (0) | 2025.05.04 |
|---|---|
| [트랜잭션 완전정복] 1편 - 진정한 의미의 트랜잭션(Transaction)이란? (0) | 2025.05.03 |