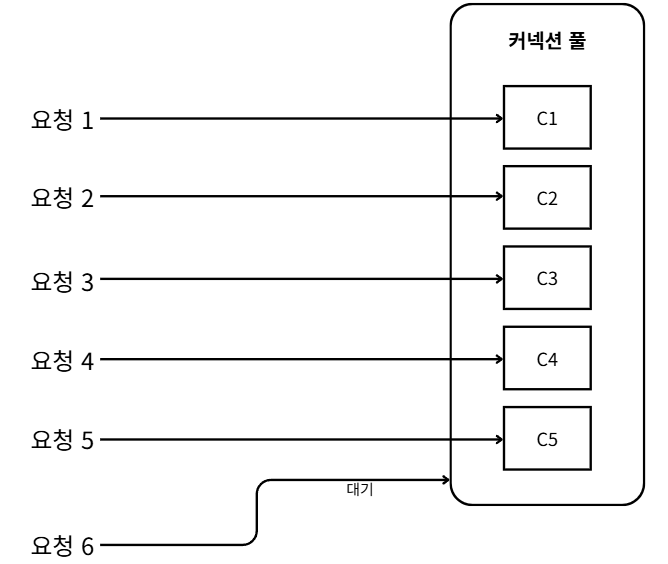
주의: 본 내용은 DB 내용에 대한 기초 지식이 어느정도 있음(DB 스캔의 작동 방식)을 가정하고 작성되었습니다.DB는 백엔드에서 가장 중요한 역할을 수행한다.DB 성능은 연동하는 모든 서버 성능에 영향을 주기 때문에, DB에 존재하는 기능을 전문가 수준으로 깊이 이해할 수 있다면 이상적이겠지만 조금만 신경 써도 DB 성능 문제를 충분히 줄이거나 없앨 수 있다.인덱스 설계예상하지 못한 테이블 풀 스캔은 DB 성능에 좋지 않은 영향을 끼친다.이를 피하기 위해서 보통 인덱스를 사용하는데, 이때 인덱스를 제대로 알고 써야 원하는 성능 효율을 얻을 수 있다.인덱스는 조회 패턴을 기준으로 설계해라.단일 인덱스 vs 복합 인덱스의 차이를 고려해라선택도(Selectivity)를 고려해라가능하다면, 커버링 인덱스를 활..