본 내용은 혼자 공부하는 데이터 분석 교재를 참고하여 작성하였습니다.
혼자 공부하는 데이터 분석 with 파이썬 - 예스24
혼자 해도 충분하다! 1:1 과외하듯 배우는 데이터 분석 자습서이 책은 독학으로 데이터 분석을 배우는 입문자가 ‘꼭 필요한 내용을 제대로 학습’할 수 있도록 구성했습니다. 뭘 모르는지조차
www.yes24.com
학습 목표
- 데이터프레임에서 불필요한 행과 열을 삭제하거나, 데이터값을 바꾸는 방법을 배워보자.
- 정규 표현식을 사용해 잘못된 값을 고치거나 누락된 값이 있는 경우 웹 스크래핑하여 얻은 값으로 채워보자.
데이터 정제란?
데이터 정제란, 데이터에서 손상되거나 부정확한 부분을 수정하고, 불필요한 데이터를 삭제하거나 불완전한 값을 교체하는 등의 작업을 의미한다.
데이터 정제는 원 데이터를 좀 더 보기 쉽고 다루기 쉽게 만드는 data wrangling, data munging의 일부로 수행되기도 한다.
수행 목표
- 열 삭제
- 행 삭제
- 중복된 행 찾기
- group by 수행하기
- 원본 데이터 업데이트 하기
- 누락된 값 처리하기
- 잘못된 값 바꾸기
- 누락된 정보 채우기
불필요한 데이터 삭제하기
열 삭제하기
열 삭제는 크게 두가지 방식으로 가능하다.
- 불리언 배열 + loc를 이용해 삭제하기
- drop() 메소드를 사용해 삭제하기
일단 시작하기에 앞서, 남산도서관 장서 대출 기록을 다운받아보자.
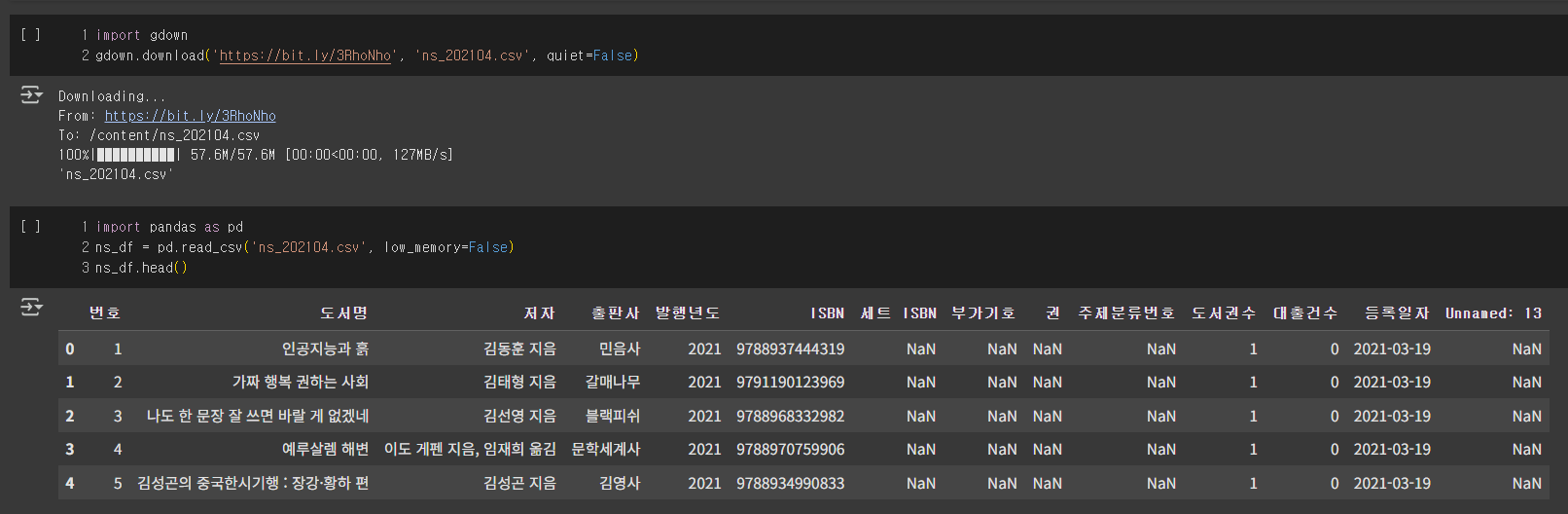
불리언 배열로 열 삭제하기
loc 메소드는 슬라이싱 방식으로 범위를 표현한다.
그렇다면 위의 '부가기호' 열을 제외하려면 어떤 방식을 선택해야 할까?
이는 불리언 배열에서 답을 찾을 수 있다.
먼저 데이터프레임의 columns 속성을 확인해보자.

Index 클래스 는 파이썬의 리스트와 유사한데, 판다스에서 다루는 배열 객체 타입이다.
판다스의 배열 객체는 내부적으로 numpy 배열을 사용하는데, 어떤 값과 비교할 때 자동으로 배열에 있는 모든 원소와 하나씩 비교해 주고, 이를 원소별 비교 라고 한다.

이제 이를 이용해 loc와 결함하여 원하는 컬럼만 추출해보자.

drop() 메소드로 열 삭제하기
drop() 메소드로 열을 삭제하려면, 첫 번째 매개변수에 삭제하려는 열 이름을 전달하고 axis 매개변수를 1로 지정한다.

동시에 여러개를 삭제하고 싶다면, 문자열 부분을 리스트 형식으로 전달하면 된다.

또한, inplace 매개변수를 True로 지정하면 현재 선택한 데이터프레임을 바로 수정할 수도 있다.

판다스는 비어있는 값을 NaN(Not a Number)으로 표시하는데, `dropna()` 메소드를 통해 NaN이 하나 이상 포함된 행이나 열을 전부 삭제할 수도 있다.
만약 모든 값이 NaN인 열만을 삭제하고 싶다면, how='all' 매개변수를 추가해주면 된다.

행 삭제하기
행 삭제 또한 크게 두가지 방식으로 삭제 가능하다.
- drop() 메소드를 통해 삭제하기
- 행 인덱스 접근으로 삭제하기
drop() 메소드를 이용해 행 삭제하기
위에서 열을 삭제할 때 사용한 axis를 0으로 설정하면 행을 삭제할 수 있는데, axis 파라미터의 기본값이 0으로 설정이 되어있기 때문에 굳이 추가하지 않아도 삭제 가능하다.

하지만 일반적으로 이렇게 숫자로 행을 지정하지는 않는다.
어떤 방법을 쓰는게 좀 더 효율적일까?
행 인덱스 접근 시 [], 슬라이싱으로 삭제하기
이전에 알아봤듯이, [] 연산자에 열 이름을 입력하면 데이터프레임의 특정 열을 선택할 수 있다.
하지만 만약 슬라이싱이나 불리언 배열을 전달하게 되면, 행을 선택 하게 된다.
코드로 직접 알아보며 각 사용 방법을 알아보자.

위와 같이 슬라이싱 식을 사용하게 되면 특정 범위의 row만 가져올 수 있게 된다.
하지만 더욱 유용한 건 위에서 컬럼을 만들 때 사용한 불리언 배열에 있다.

위에서 설명한 '원소별 비교'를 이용해 특정 조건을 만족하는 행만 필터링할 수 있게 되었다.
이를 이용해 다양한 조건식을 만들 수 있다.

중복된 행 찾기
이번엔 중복된 행을 찾아보자.
판다스 데이터프레임의 중복된 행은 duplicated() 메소드를 사용하여 검사할 수 있다.
해당 메소드는 중복된 행 중에서 처음 만난 행은 False를, 두번 이상 등장한 행은 True를 반환한다.

중복이 하나도 없다니 어떻게 된 일일까?
다시보니 '번호' 열이 모두 고유한 값을 갖고 있기 때문에, 중복된 행이 나올 수가 없었다.
도서명, 저자, ISBN 값만 보고 다시 한번 중복된 행의 갯수를 파악해보자.

무려 22096건의 중복된 데이터가 등장하는 것을 확인할 수 있었다.

'파친코'의 경우 책이 1권/2권으로 나누어져 있는 것을 확인할 수 있었다.
'보건교사 안은영'은 한 권짜리 도서인데 두 권이 등록되어 있다. 아마 인기가 많아 도서관에서 한 권 더 구입한 것으로 보인다.
그룹 별로 모으기
이번엔 앞으로 어떤 도서가 인기 있을지 파악하고 싶으므로, 같은 도서의 대출건수는 하나로 합치는 것이 좋아보인다. groupby() 메소드를 이용해 하나로 합쳐보자.
sql을 다뤄본 적이 있다면 익숙할 것이다.

원본 데이터 처리하기
이제 구한 대출건수를 원본 데이터프레임에 추가하려고 한다.
그런데 원본 데이터프레임에는 [도서명/저자/ISBN/권]을 고유 키로 봤을 때 중복된 데이터가 존재한다.
따라서 이 중복된 데이터를 제거하고 고유한 행만 선택하여 해당 대출건수를 추가해보자.
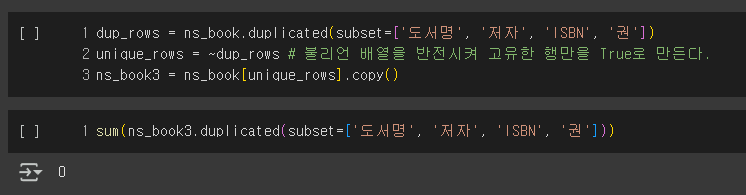
예상대로 고유한 행만 잘 골라냈음을 확인할 수 있었다.
이제 만들어낸 고유한 행만 모아둔 ns_book3의 인덱스를 loan_count 데이터프레임의 인덱스와 동일하게 만들어보자.

인덱스를 loan_count의 인덱스와 일치시켰기 때문에, 이제 update() 메소드를 이용해 특정 컬럼을 간단하게 업데이트 할 수 있게 되었다.

당장 값이 바뀐 것을 확인하긴 어렵다. 한번 대출건수>100 인 값들을 찾아보자.

중복된 도서들을 합쳤더니, 대출 건수가 100회 이상인 책이 239건이나 증가하였다.
위와 같이 데이터 정제를 통해 좀 더 좋은 데이터를 얻을 수 있다.
마무리로 인덱스 열을 해제하여 다시 넘버링으로 인덱스가 세어질 수 있게 돌려놓자.

이제 보니, 원본 데이터프레임과 컬럼의 순서도 약간 달라졌다.
해당 문제를 해결하기 위해, 기존 데이터프레임의 열 순서대로 바꿔보자.

지금까지 수행한 작업들을 하나의 함수로 만들어보자.

만든 파이썬 함수가 지금까지 수행한 작업과 동일한지 검사해보자.

잘못된 데이터 수정하기
판다스는 기본적으로 누락된 값을 NaN(Not a Number)로 표현한다.
해당 NaN 을 채우는 여러 방법들을 알아보며, 좀 더 견고하고 완성된 데이터를 만들어보도록 하자.
데이터프레임의 상세한 정보는 df.info() 메소드를 통해 알아볼 수 있다.

추정이 아닌 정확한 메모리 사용량을 알고 싶다면, memory_usage='deep'을 매개변수로 주면 된다.
이렇게 직접 셀 수도 있지만, 이미 판다스에는 훨씬 간단한 isna()라는 메소드가 존재한다.
해당 메소드는 각 행이 비어 있는지를 나타내는 불리언 배열을 반환한다.

감이 좋은 사람이라면, sum() 집계 함수가 떠오를 것이다!
이어서 sum을 바로 호출해보자.

참고: 판다스의 NaN은 넘파이의 np.nan을 사용한다.
누락된 값 바꾸기(1): loc, fillna() 메소드
세트 ISBN 열은 대부분의 값이 비어 있다. 이 누락된 값을 NaN이 아니라 빈 문자열('')로 바꿔보자.
먼저 loc 메소드를 이용해 누락된 값을 원하는 값으로 바꿔보자.
그러기 위해선 먼저 누락된 값을 찾아 불리언 배열로 반환해야 한다.

위와 같이 간편하게 빈 문자열로 대체하였고, 결과적으로 누락된 행의 개수는 0개가 되었다.
다른 방법으로는 fillna()가 있다.

해당 함수는 모든 NaN을 특정 값으로 대체한다.
위에서는 모든 NaN을 '없음' 문자열로 바꾸는데, 각 열은 되도록이면 단일 자료구조가 되어야 한다는 내용 기억나는가?
위와 같은 방식을 남용한다면, 판다스가 내부에서 해당 컬럼을 object 타입으로 다운캐스팅하여 int 자료형과 같은 기본 자료형의 이점을 누리지 못하고, 연산의 효율성이 저하될 것이다.
따라서 다음과 같이 사용하는 것이 좋다.

누락된 값 바꾸기(2): replace() 메소드, 정규 표현식(regex)
replace() 메소드는 NaN은 물론 어떤 값도 바꿀 수 있는 편리한 메소드이다.
replace() 메소드는 세가지 방식으로 사용할 수 있다.
replace(원래 값, 새로운 값)replace([원래 값1, 원래 값2], [새로운 값1, 새로운 값2])replace({열 이름: 원래 값}, 새로운 값)
여기서 원래 값을 찾을 때, 정규 표현식을 사용할 수 있다.
추천하는 정규 표현식 학습 사이트 - https://regexone.com/
정규 표현식을 이용하면, 값의 특정 부분만을 수정하는 것도 가능하니, 한번 문제를 쭉 풀어보는 것을 권장한다.
RegexOne - Learn Regular Expressions - Lesson 1: An Introduction, and the ABCs
Regular expressions are extremely useful in extracting information from text such as code, log files, spreadsheets, or even documents. And while there is a lot of theory behind formal languages, the following lessons and examples will explore the more prac
regexone.com

문제 해결: 1988년에 출간한 어떤 도서를 찾을 수 없어요!
왜 1988년에 출간한 도서를 찾을 수가 없는걸까?
한번 이유를 알아보자.
먼저 발행연도 컬럼의 정보를 알아보자.

발행년도의 타입이 정수가 아니라 object 타입임을 알 수 있었다.
뭔가 이상하다. 한번 int64 타입으로 바꿔보자.

1988.을 정수로 바꿀 수 없다고 한다.
현재 단순 문자열로 이루어진 발행년도 값이 존재한다는 것을 확인할 수 있었다.
과연 어떤 행들이 문제인지 한번 갯수를 비교해보도록 하자.

20개의 행이 1988이라는 값으로 저장되어 있지 않은 것을 확인할 수 있었다.
확실하게 알기 위해서, 발행년도 값에 숫자가 아닌 문자를 포함하는 모든 행을 찾아보자.
contains() 메소드의 na 매개변수를 True로 지정하여 연도가 누락된 행을 True로 표시하고, 문자열로 보도록 한다.

1777개의 행이 단순한 정수가 아닌 값들을 발행년도로 갖고 있었다.
이 값들을 차근차근 4자리의 발행년도로 바꿔보자.
먼저 연도를 나타내는 숫자 4개를 추출해보자.

정규식에 맞게 년도가 바뀌었다.
다시 숫자 이외의 문자가 들어간 행의 개수와 데이터를 확인해보자.

1777개에서 67개로 줄었다.
이제 변환되지 않은 값은 NaN이거나 네자리 숫자가 아닌 값이다.
이런 값은 임의로 -1로 바꾸고, 일단 발행년도 열의 데이터 타입을 정수형인 int64로 바꿔보자.
ns_book5.loc[unknown_year, '발행년도'] = '-1'
ns_book5 = ns_book5.astype({'발행년도': 'int64'})이게 끝이 아니다.
연도 중 이상하게 아주 큰 값이나 작은 값이 들어있는 경우(단기, 즉 단군기원을 사용하는 경우)도 있으므로, 이를 필터링해보자.
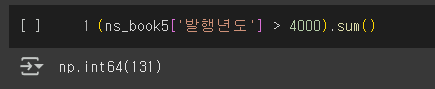
무려 131개의 책이 발행년도가 4000을 넘기고 있었다.
4000년이 넘는 연도에서 2333년을 빼서 서기로 바꾼 다음, 4,000년이 넘는 도서가 있는지 확인해보자.

2333을 빼주어도 연도가 이상하리만큼 높은 책들이 존재한다.
이런 도서도 모두 -1로 표시해두자.
ns_book5.loc[dangun_year, '발행년도'] = -1연도가 낮은 책들도 한번 봐보자.

여전히 잘못된 값이 있다.
이 도서들도 연도를 -1로 설정하고 전체 행 개수를 확인해보자.

총 86권이 잘못 저장되었거나 알 수 없다.
이제 '발행년도' 열을 비롯해 다른 열에 잘못되거나 누락된 값들을 채워보자.
누락된 정보 채우기
데이터 분석에 있어서, '도서명', '저자', '출판사', '발행년도' 열이 분석에 중요하다고 가정하자.
따라서 이 4개의 열에는 누락된 값이 있으면 안되기 때문에, 해당 행들을 웹 스크래핑을 이용해 채워야 한다.
다행히도 제목, 저자, 출판사, 발행년도 모두 검색창에서 모두 획득할 수 있으니, 여기서 하나씩 가져와보도록 하자.

BeautifulSoup를 이용해 이 5268개의 행을 채워보자.
import requests
from bs4 import BeautifulSoup
import re
def get_book_info(row):
"""
도서명, 저자, 출판사, 발행년도를 채우는 메소드.
"""
title = row['도서명']
author = row['저자']
pub = row['출판사']
year = row['발행년도']
url = 'https://www.yes24.com/product/search?domain=BOOK&query={}'
r = requests.get(url.format(row['ISBN']))
soup = BeautifulSoup(r.text, 'html.parser')
try:
if pd.isna(title):
title = soup.find('a', attrs = {'class':'gd_name'}).get_text()
except AttributeError:
pass
try:
if pd.isna(author):
authors = soup.find('span', attrs = {'class':'info_auth'}).find_all('a')
author_list = [auth.get_text() for auth in authors]
author = ', '.join(author_list)
except AttributeError:
pass
try:
if pd.isna(pub):
pub = soup.find('span', attrs = {'class':'info_pub'}).find('a').get_text()
except AttributeError:
pass
try:
if year == -1:
year_str = soup.find('span', attrs={'class': 'info_date'}).get_text
year = re.findall(r'\d{4}', year_str)[0]
except AttributeError:
pass
return title, author, pub, year이제 만든 함수를 예제로 적용해보자.

이렇게 웹 스크래핑을 이용해 부족한 값들을 채워보았다.
'AI Repository > 기초 통계학' 카테고리의 다른 글
| [개발자를 위한 필수 수학] 확률의 기초 (0) | 2025.07.23 |
|---|---|
| [혼자 공부하는 데이터 분석] 통계의 기초 구성 요소와 Matplotlib의 기본 구조 (0) | 2025.07.22 |
| [혼자 공부하는 데이터 분석] 데이터 분석 기초를 시작하며 (0) | 2025.07.11 |
| 공공 데이터셋 탐색 사이트 (0) | 2025.07.11 |
| [개발자를 위한 통계학 찍먹하기] 0편 - 동기 (0) | 2025.05.06 |