MountainCar - 단순 DQN으로 풀기
https://gymnasium.farama.org/environments/classic_control/mountain_car/
Gymnasium Documentation
A standard API for reinforcement learning and a diverse set of reference environments (formerly Gym)
gymnasium.farama.org
요구사항 정의

Mountain Car MDP는 사인곡선의 바닥에 확률적으로 배치된 자동차로 구성된 결정론적 MDP이다.
가능한 동작은 자동차에 양방향으로 적용할 수 있는 가속뿐이다.
이 MDP의 목표는 오른쪽 언덕 꼭대기의 목표 상태에 도달하기 위해 자동차를 전략적으로 가속하는 것이다.
Mountain Car Continuous 와 다름에 유의하자.
액션 공간
3가지의 개별적인 결정론적 행동이 있다.
- 0: 좌측으로 가속
- 1: 가속 X
- 2: 오른쪽으로 가속
동역학
동작이 주어지면 산악 차량은 다음과 같은 전환 역학을 따른다.

여기서
- 힘 = 0.001
- 중력 = 0.0025
이다.
양쪽 끝의 충돌은 비탄성이며, 벽과의 충돌 시 속도는 0으로 설정된다.
위치는 [-1.2, 0.6]범위에 , 속도는 [-0.07, 0.07]범위에 고정된다 .
보상
목표는 가능한 한 빨리 오른쪽 언덕 위에 놓인 깃발에 도달하는 것인데, 이를 위해 에이전트는 각 타임스텝마다 -1의 보상을 받으며 페널티를 받는다.
시작 상태
자동차의 위치는 [-0.6, -0.4] 범위의 균일한 난수 값으로 지정된다 . 자동차의 시작 속도는 항상 0으로 지정된다.
에피소드 종료
다음 중 하나가 발생하면 에피소드가 종료된다.
- 종료 : 차량의 위치가 0.5 이상(오른쪽 언덕 위의 목표 위치)
- 잘림: 에피소드의 길이 200을 넘었을 경우.
파라미터
Mountain Car에는 gymnasium.make에 대한 두 개의 매개변수render_mode & goal_velocity가 있다 .
reset 시, 이 options매개변수를 통해 사용자는 새로운 임의 상태를 결정하는 데 사용되는 범위를 변경할 수 있다.
API 를 실제로 살펴보자.

MountainCar 의 다음 상태 전이를 나타내는 'step' 함수는 특정 행동했을 때 결과인 새로운 관찰(obsType)을 건네받는다.
즉, 환경에 따른 적절한 판단을 해줄 에이전트가 필요하다.
어떤 기법을 사용하는 게 좋을까?
단순 강화 학습 기법
- DP
- 몬테카를로
- TD/SARSA
- Q-Learning
심층 강화학습 기법
- 모델 기반
- 모델 학습
- 알파고
- 알파제로
- 주어진 모델 이용
- World Models
- MBVE
- 모델 학습
- 모델 프리
- 정책 기반
- 정책 경사법
- PPO
- TRPO
- REINFORCE
- 정책 경사법
- 가치 기반
- DQN
- Double DQN
- 행위자-비평자 (정책 + 가치 기반)
- A2C
- A3C
- DDPG/TD3
- SAC
- 정책 기반
간단한 에이전트부터 구현해보자.
뭐부터 해볼까?
지금 현재 나는 그냥 Q-Learning 이 최고로 알고있었다.
좀 더 내용을 정리해보자.
- 모델을 자세히 알고있나?
- MDP 전이 p/보상 r을 알고 있으면 -> DP or 조금 더 빠르게 MCTS가 제일 빠를듯
- 모델 없음
- 탐험 중 위험/전이가 확률적 -> SARSA
이제 설계를 시작하려고 하니, 뭐가 필요한지 기억이 나기 시작했다.
- 어떤 것을 현재 상태로 둘 것인가?
- x축 위치
- 속도
- 내가 가하는 액션은 어떤 액션인가?
- 현재 주어진 정보는 특정 방향으로 가속밖에 없다.
- 그 가속의 변화는 어떻게 준다고?

즉, 현재는 보상과 전이 확률(결정론적)이 모두 알려져 있다.
또한, 탐험 자체에는 크게 확률적인 요소가 없어보인다.
정해진 위치에선 정해진 중력만큼 받는다.
즉, 상태가 그렇게까지 많진 않다.
그럼 DP로 일단 먼저 생각해보자.
주의) 후에 잘못됨을 알고 이대로 실행하지 않습니다.
DP - 가치 반복법
DP는 최적 정책을 "평가-개선 반복"을 통해 탐색한다.
즉, 정책 pi를 수행하고,
이를 상태 가치 함수 V로 평가한 뒤, 이를 통해 새로운 정책 mu를 탐욕적으로 도출해낸다.
정책 개선 단계의 탐욕화

DP 갱신식(정책 평가)

하지만 여기서 다시 '정책 개선' 단계를 거치면, 해당 DP 갱신식이 탐욕적 방식으로 바뀐다.
따라서 DP 갱신식의 정책을 결정적 정책 mu로 취급하여 다음과 같이 단순화할 수 있다.

자세히 보면 정책 개선 단계의 탐욕화 시 사용하던 식이, V'(s) 임을 알 수 있다.
이 중복된 계산을 하나로 묶어, '정책 개선 + 정책 평가' 함수를 만들면 다음과 같이 정의할 수 있다.

게다가 이제는 정책을 결정하지 않고도 가치함수를 갱신할 수 있었다.
잠깐 확실하게 하고 넘어가자면,
고전적 강화학습 알고리즘은 가치 함수를 통해 각 다음 행동의 가치를 평가하고, 이를 통해 다음 행동을 결정했다.
즉, 결과인 '행동했을 때의 가치(수익)'에 대한 학습을 수행했다.
하지만 정책 경사법과 같은 알고리즘은 신경망을 통해 '직접 정책을 학습'시켜, 가치함수의 학습 없이 최적 정책을 탐색한다.
하지만 베이스라인, 액터-크리틱과 같은 기법을 위해 정책 경사 계열 알고리즘도 결국에 가치 함수를 사용하긴 한다.
이제 알고리즘을 수행해보자.
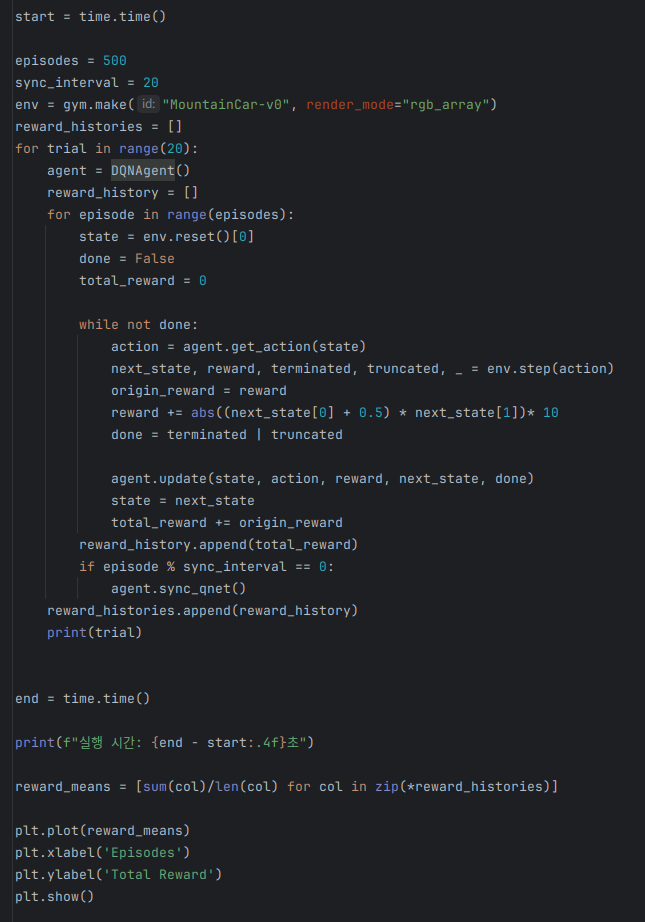
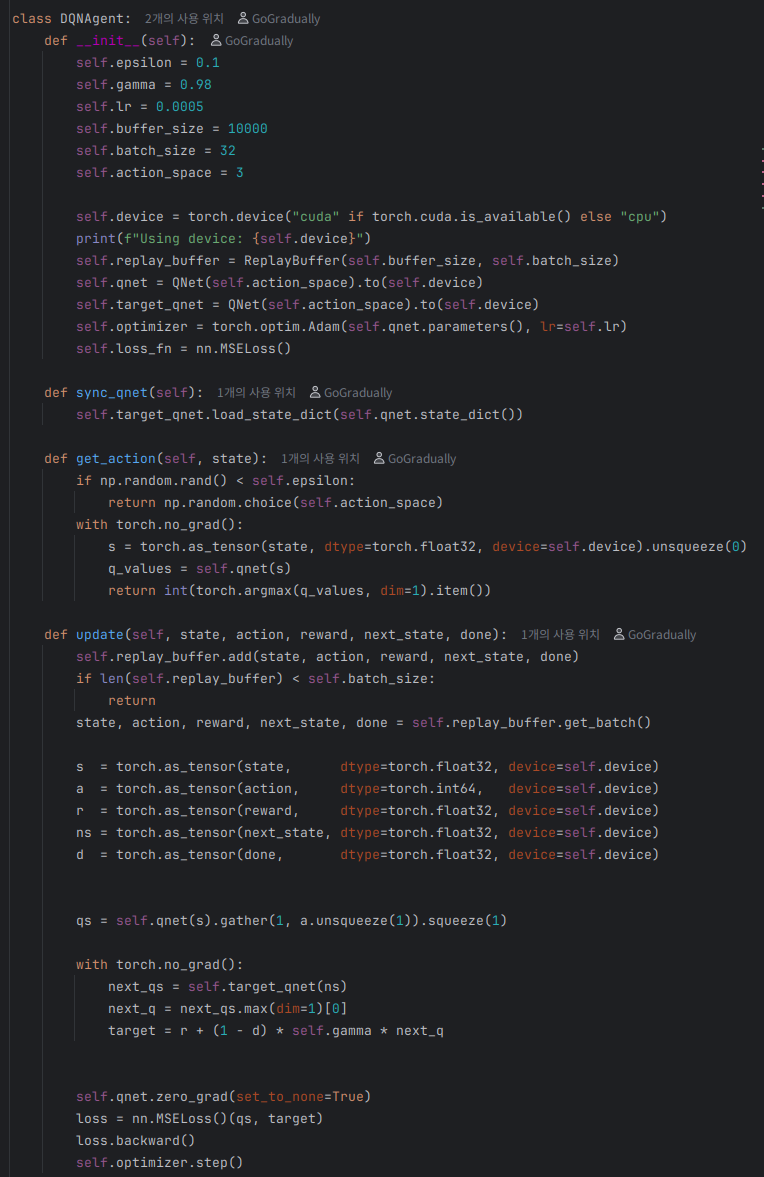
단순한 에이전트에 필요한 get_action() 메소드와 update() 메소드를 구현해보자.
각 보상마다 -1의 보상을 획득한다. (supportFloat)
즉, 빨리 도착할수록 total reward가 높게 나온다.
생각해보니 공간 자체가 연속적이다.
그럼 DP로 하기엔 필요한 상태 s가 너무 많다.
행동의 갯수가 적었을 뿐이었다...
이걸 각 위치마다 DP로 저장하면, 너무 많은 상태가 들어갈 듯 했다.
(이걸 왜 생각 못했지?)
다시 생각해보자.
- 연속적인 공간을 각 상태별로 상태 가치 함수로 만들기에는 메모리 부하가 심하다.
- 고전적 상태 가치 함수를 사용할 경우, 연속적 공간에 사용하기에는 무리가 있다.
따라서,
- 해당 연속 공간을 이산 공간으로 바꾸고, TD를 도입
- 가장 가까운 위치의 행동대로 움직이기
- 신경망의 도입
- 상태의 연속성 살려보기
이번에는 연습 겸, 신경망을 도입해보겠다.
DQN 사용해보기
이번엔 신경망을 도입해보자.
파이토치를 이용해 Q 함수를 나타내는 신경망과 그를 사용하는 에이전트를 구현해야 한다.

학습이 잘 안된다...
수익이 아예 잡히질 않는데, 미래 시점의 보상을 전혀 예상하지 못하는 것 같다.
문제를 다시 생각해보자.

탐색을 아무리 수행해도 제대로 된 학습을 수행하지 못하는 시나리오이다.
결국 저 정상을 한번은 찍어야 수익이 잡히는데, 저 지점을 탐색하기가 어려운 상황이다.
탐색의 비중을 좀 더 높여볼까?
입실론을 0.5로 높혀봤다.
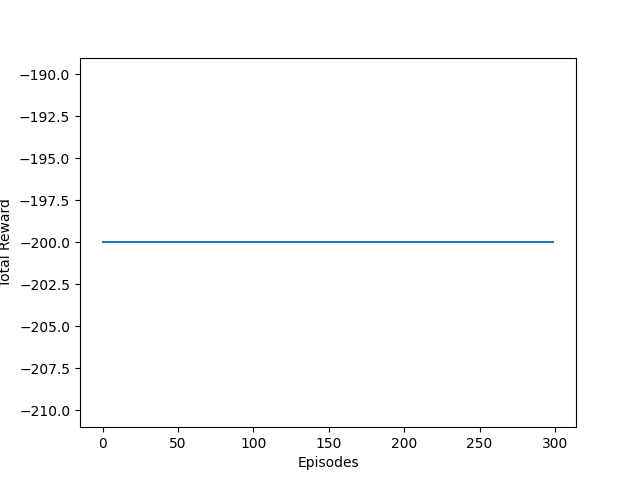
여전히 같은 결과를 볼 수 있었다.
보상을 받는 상태가 매우 도달하기 힘들 경우, 어떻게 문제를 풀 수 있을까?
- 내가 직접 추가로 보상을 정의한다.
- 우측 목적지에 가까워질수록 보상을 크게?
- 그럴 경우, "그네타기" 식 높은 곳 착륙 전략이 불가능해진다.
- 가운데에서 멀어질수록 보상을 크게?
- 왼쪽으로 빠져나갈 수도 있을 듯 한데
- 뭐가 되었든, 내가 주는 포상보다 실제 보상이 작지 않도록 보상의 크기를 잘 정해야 한다.
- 이를 리워드 셰이핑(Reward Shaping)이라 한다.
- 우측 목적지에 가까워질수록 보상을 크게?
- 보상 자체도 학습시키는 방법은 없나?
일단, 속도와 위치에 대한 정보가 위에서 수식으로 주어졌으니, 이걸 이용해 적절한 보상을 추가해보자.
- 에너지 보존 법칙을 이용해 위에 정의된 수식대로 위치에너지+운동에너지를 보상으로 추가하기
- 단순히 가운데에서 멀리 떨어지고, 속도가 빠를수록 보상으로 추가하기
나는 여기서 두번째 안을 시도해보았다.

이렇게 추가 후 에포크도 1000정도로 수행해봤더니, 이제 어느정도 성공하는 수준까지 가긴 한다.

그런데 그래프가 너무 지저분하다.
이 에피소드들 자체를 100번 반복해서 평균값으로 그려보자.
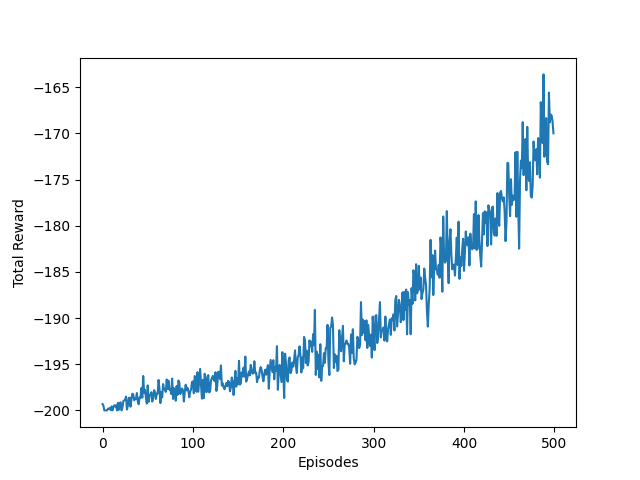
이제 어느정도 가시성이 좋아졌다.
그런데, 필요한 에피소드도 너무 길고, 학습이 빠르게 진행되지도 않았다.
캐글의 Mountain Car 튜토리얼에선 50에피소드만에 도달한다고 알려져있다.
이는 곧 학습의 효율성이 낮음을 의미한다.
어떻게 이를 더욱 최적화할 수 있을까?
- 하이퍼 파라미터 튜닝
- 할인율 높이기
- 어차피 유한 에피소드인데, 할인율이 아예 1이면 안되나?
- 이는 적절한 Validation 과정을 수행해서 하면 좋지 않을까?
- 따로 공부할 필요가 있을듯. RL의 하이퍼파라미터 튜닝은 기억에 없는 내용임.
- 할인율 높이기
- 이산적인 공간으로 근사하기
- 이산적인 공간으로 근사하고, Q-Learning을 활용하는 것이 오히려 학습률을 높일 가능성이 존재함.
- 애초에 공간 자체가 연속적인 공간이고, 정책도 오차에 크게 영향을 받을 환경 모델이 아님.
- 보상 정책의 변경
- 좀 더 좋은 보상 정책 탐색
- 위치와 속도를 평균이 0, 표준편차가 1인 분포로 z-score 정규화
- 위치와 속도의 보상의 크기 튜닝
학습의 속도 문제인걸 보니, 하이퍼 파라미터 튜닝 혹은 어딘가에 중요한 판단 기준이 제대로 전파되지 않는 것 같은데,
아직 확실한 답이 서지 않아 근거를 갖고 시도를 해봐야 할 듯 하다.
참고) 소스코드