[밑바닥부터 시작하는 딥러닝] seq2seq, Encoder-Decoder
본 내용은 밑바닥부터 시작하는 딥러닝 2도서를 참고하여 작성되었습니다.
밑바닥부터 시작하는 딥러닝 2 - 예스24
직접 구현하면서 배우는 본격 딥러닝 입문서 이번에는 순환 신경망과 자연어 처리다! 이 책은 『밑바닥부터 시작하는 딥러닝』에서 다루지 못했던 순환 신경망(RNN)을 자연어 처리와 시계열 데
www.yes24.com
그동안 RNN과 LSTM의 구조와 구현을 자세하게 살펴봤다.
먼저, 이제 이것들을 이용해서 "문장 생성"을 구현해보자.
그리고 이를 확장한 seq2seq를 다뤄보며, 인코더-디코더 구조와 그 원리를 이해해보도록 하자.
언어 모델을 사용한 문장 생성
RNN을 사용한 문장 생성의 순서
앞장에서 LSTM계층을 이용하여 언어 모델을 구현했는데, 그 모델의 신경망 구성은 아래 그림처럼 생겼다.

그럼 이제 언어 모델에게 문장을 생성시키는 순서를 생각해보자.
이번에도 "you say goodbye and I say hello." 라는 말뭉치로 학습한 언어 모델을 예로 생각해볼 것이다.
이 학습된 언어 모델에 "I" 라는 단어를 주면 어떻게 될까?
아마 아래와 같은 확률분포를 출력할 것이다.

언어 모델은 주어진 단어들에서 다음에 출력하는 단어의 확률분포를 출력한다.
이 결과를 기초로 다음 단어를 새로 생성하려면 어떤 방식이 있을까?
여기에는 크게 두가지 방식이 있다.
- 결정론적 방법
- 결정론적 방법은 가장 높은 확률분포 값을 갖는 하나를 출력하는 방식이다.
- 예측가능한 결과를 내놓는다.
- 확률론적 방법
- 확률론적 방법은 해당 확률대로 임의로 샘플링을 수행하고, 샘플링된 단어 하나를 출력하는 방식이다.
- 예측불가능한 결과를 내놓을 수 있다.
이왕이면 매번 다른 단어가 나오는 것이 재밌을테니, 확률론적 방법을 수행해보자.
아래 그림은 확률분포로부터 샘플링을 수행한 결과로 "say"가 선택된 경우를 보여준다.
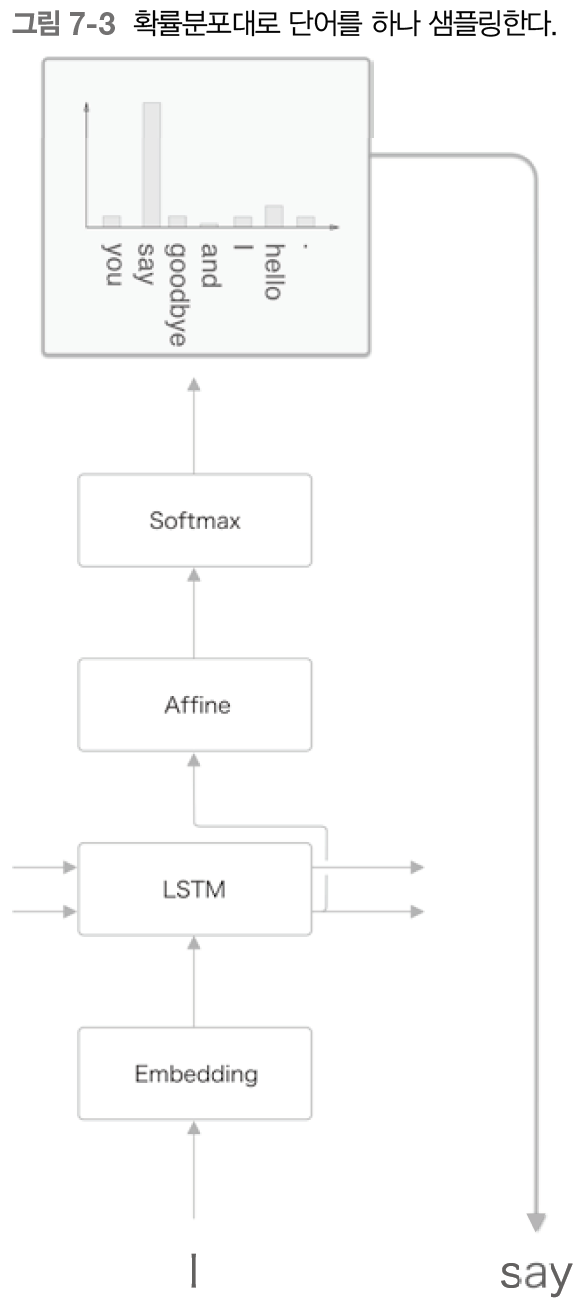
LSTM은 시계열 데이터를 받기 때문에, 이 say를 다시 언어모델에 입력할 수 있을 것이다.
그럼 방금 생성한 단어인 "say"를 다시 언어모델에 입력하여 다음 단어의 확률 분포를 얻고, 그 샘플링을 반복하자.

그럼 그 다음 단어로 적당한 단어를 확률적으로 샘플링하여 가져올 것이다.
위 그림에선 "hello"를 가져왔다.
여기서 주목해야 할 것은 이렇게 생성한 문장은 훈련 데이터에는 존재하지 않는, 말 그대로 새로 생성된 문장이라는 것이다.
왜냐하면 언어 모델은 훈련 데이터를 암기한 것이 아니라, 훈련 데이터에서 사용된 단어의 정렬 패턴을 학습한 것이기 때문이다.
만약 언어 모델이 말뭉치로부터 단어의 출현 패턴을 올바르게 학습할 수 있다면, 그 모델이 새로 생성하는 문장은 우리 인간에게도 자연스럽고 의미가 통하는 문장일 것으로 기대할 수 있다.
문장 생성 구현
이제 문장을 생성하는 코드를 구현해보자.
우리는 이 클래스를 RnnlmGen으로 정의할 것이다.

행렬의 형상을 맞추기 위해, reshape(1, 1)을 수행했다.
이는 model의 predict() 메소드가 미니배치 처리를 수행하기 때문인데, 따라서 입력을 2차원 배열을 주어야 한다.
그래서 단어 ID를 하나만 입력하더라도 미니배치 크기를 1로 간주해 1x1 넘파이 배열로 reshape 한다.
특이한 매개변수로는 skip_ids가 있는데, 이녀석은 샘플링되지 않아야 하는 단어의 리스트를 받는 용도로 사용된다.
이런게 왜 필요한가 싶을 수 있는데, 이 인수는 PTB 데이터셋에 있는 unk나 N 등, 전처리된 단어를 샘플링되지 않게 하는 용도로 사용한다.
이제 이걸로 문장을 생성한 결과를 확인해보자.
이번엔 아무런 학습도 수행하지 않은 상태에서 문장을 생성한다.
문장 생성 코드는 아래와 같다.

그 결과, 아래와 같은 문장이 생성되었다.
you acres watched linking developed until however required environmentalism aspect philippines facsimile congress repayment backup faa kevin embarrassing similarly tabloid various taiwan requested temporarily proposes stated maintained boesel used paterson principles conduct politicians wild contrasts salesmen hees economics supposed believes repair giorgio plc binge shere taiwanese million hud rehabilitation slipped bankruptcy policy leaped wives toronto affecting interview liberty s.p bancroft dismiss entry telerate rouge test studios walks ministers poll costly daly shook freeman bay onto chemistry cars gary telesis recognized secure knew bozell obligations books merchandising modern pioneer broaden congressional blueprint examiner datapoint attacks long-awaited throw anniversary restaurants weakened care학습되지 않은 모델을 넣은 탓에, 엉터리로 단어들을 나열한 글이 출력되었다.
이번엔 LSTM을 공부하며 학습시켰던 가중치를 가져와서 사용해보자.
우선 RnnlmGen이 상속받는 클래스를 BetterRnnlm으로 바꾸었다.

또한, 이전 시간에 학습했던 가중치를 로드해 예측을 수행하도록 모델에 파라미터를 추가했다.

그 결과는 아래와 같다.
you was said the u.s. attorney who owns cbs communications inc.
mr. boyd was a beautiful commitment.
the biggest word in the u.s. in detail sees how well the client ought to be in the united states for themselves and they are as temporary and suggests that mancuso has ignore much of them.
turkey is a political relationship with the israeli embassy.
it would be a classic market we must adopt a scrap standard of capital with some members of the cray-3 and pull the problems of ultimately the headline harbors in the state.
even각자 생성되는 문장이 다를 것이다.
하지만 이번에는 비교적 의미가 통하는 문장이 생성되었다.
주어-동사-목적어 패턴이 어느정도 잘 구성되어 있는 것도 확인할 수 있었다.
- “the u.s. attorney who owns…”
- “Mr. Boyd was…”
- “Turkey is…”
- “we must adopt…”
이걸 좀 더 개선할 방법이 없을까?
seq2seq (시퀀스 - 투 - 시퀀스)
세상에는 시계열 데이터가 넘쳐난다.
언어, 음성, 동영상 데이터는 모두 시계열 데이터이다.
그리고 이러한 시계열 데이터를 또 다른 시계열 데이터로 변환하는 문제도 숱하게 생각할 수 있다.
이처럼 입력과 출력이 시계열 데이터인 문제는 아주 많다.
지금부터 우리는 시계열 데이터를 다른 시계열 데이터로 변환하는 모델을 생각해볼 것이다.
이를 위한 기법으로, 여기에서는 2개의 RNN을 이용하는 seq2seq라는 방법을 살펴볼 것이다.
seq2seq의 원리
seq2seq는 Encoder-Decoder 모델이라고도 한다.
이름이 말해주듯이 여기에는 2개의 모듈, Encoder와 Decoder가 등장한다.
문자 그대로 Encoder는 입력 데이터를 인코딩(부호화)하고, Decoder는 인코딩된 데이터를 디코딩(복호화)한다.
이를 정리하면 아래와 같다.
seq2seq는
- 인코더는 입력 값을 고정 길이 벡터로 변환하고,
- 출력 값은 디코더가 그 고정 길이 벡터를 통해 예측으로 결정하는 작업
을 수행한다.
이해가 안간다면 이 글을 끝까지 읽고 다시 읽어보자.
예를 들어 우리말을 영어로 번역하는 경우를 생각해보자.
"나는 고양이로소이다"라는 문장을 "I am a cat"으로 번역하고자 하면 아래와 같은 구조를 띌 것이다.

이때 인코더가 인코딩한 정보에는 번역에 필요한 정보가 조밀하게 응축되어 있다.
그리고 Decoder는 조밀하게 응축된 이 정보를 바탕으로 도착어 문장을 생성한다.
이것이 seq2seq의 전체 그림이다. Encoder와 Decoder가 협력하여 시계열 데이터를 다른 시계열 데이터로 변환하는 것이다.
그리고 Encoder와 Decoder로는 RNN을 사용할 수 있다.
Encoder의 기본 구성

Encoder는 RNN을 이용해 시계열 데이터를 h라는 은닉 상태 벡터로 변환한다.
지금 예에서는 LSTM을 이용했지만, '단순한 RNN'이나 GRU 등도 가능하다.
여기에서는 우리말 문장을 단어 단위로 쪼개 입력한다고 가정한다.
그런데 Encoder가 출력하는 벡터 h는 LSTM 계층의 마지막 은닉 상태이다.
이 마지막 은닉 상태 h에 입력 문장(출발어)을 번역하는 데 필요한 정보가 인코딩된다.
여기에서 중요한 점은 LSTM의 은닉 상태 h는 고정 길이 벡터라는 사실이다.
그래서 인코딩한다라 함은 결국 임의 길이의 문장을 고정 길이 벡터로 변환하는 작업이 된다.

위 그림에서 보듯, Encoder는 문장을 고정 길이 벡터로 변환한다.
여태까지 LSTM에서 배운 내용이랑 달라서 헷갈릴 수 있는데,
인코더는 LSTM에서 출력하던 각 '시각별' 은닉 상태는 출력하지 않고, '모든 문장을 통과한 뒤 나온' 은닉 상태만 출력한다.
그럼 이전에 계산하고 나왔던 은닉 상태들은 쓸데가 없을까?
그 질문에 대한 대답은 Attention Mechanism에서 알 수 있다.
그렇다면 Decoder는 이 인코딩된 벡터를 어떻게 '요리'하여 도착어 문장을 생성하는 걸까?
Decoder의 기본 구성

디코더는 딱 하나만 제외하고 앞 절의 신경망과 완전히 같은 구성이다.
바로 LSTM계층이 벡터 h를 입력받는다는 것이다.
참고로, 앞 절의 언어 모델에서는 LSTM계층이 아무것도 받지 않았다.
굳이 따지자면, 은닉 상태로 '영벡터'를 받았다.
이 사소한 차이가, 언어 모델을 Decoder로 탈바꿈시킨다.
그럼 이제 인코더와 디코더를 연결한 계층 구성을 볼 차례이다.

이와 같이, seq2seq는 LSTM 두개로 구성된다.
이때, LSTM계층의 "은닉 상태"가 Encoder 와 Decoder를 이어주는 '가교'가 된다.
순전파 때는 Encoder에서 인코딩된 정보가 LSTM계층의 은닉 상태를 통해 Decoder에 전해진다.
그리고 seq2seq의 역전파 때는 이 '가교'를 통해 기울기가 Decoder로부터 Encoder로 전해진다.
예제 - 시계열 데이터 변환용 장난감 문제
이쯤에서 seq2seq를 실제로 구현해봤으면 하니, 우선 지금부터 다룰 문제에 관해 설명하겠다.
우리는 시계열 변환 문제의 예로 '더하기'를 다룰 것이다.
이는 "57+5"를 보면 "62"를 출력하도록 하는 모델을 설계한다는 뜻이다.

이와 같이 머신러닝을 평가하고자 만든 간단한 문제를 '장난감 문제(toy problem)'이라 한다.
현재 문제를 보면 알겠지만, 덧셈 연산은 하나의 시계열 데이터라기보단 여러 시계열 데이터의 집합 에 가깝다.
즉, 다음에 올 단어가 정답으로 이미 존재하고, 디코더는 식의 좌변에서 우변을 예측할 수 있어야 한다.
그런데 좌변/우변의 데이터의 순서가 중요한 시계열 데이터인 것이다.
여기서 디코더는 좌변의 데이터에서 우변의 데이터를 출력할 수 있어야 한다.
seq2seq는 덧셈의 논리에 대해 아무것도 모른다. seq2seq는 덧셈의 '예'로부터, 거기서 사용되는 문자의 패턴을 학습한다.
과연 이런 식으로 해서 덧셈의 규칙을 알 수 있을까? 이 점이 바로 이번 문제의 볼거리다.
가변 길이 시계열 데이터
그런데 우리는 지금까지 word2vec이나 언어 모델 등에서 문장을 '단어' 단위로 분할해왔다.
하지만 문장을 반드시 단어 단위로 분할해야 하는 것은 아니다.
실제로 이번 문제에서는 단어가 아닌 '문자'단위로 분할 및 의미 부여를 수행할 것이다.
예컨데 ['5', '7', '+', '5'] 이렇게 분할하겠다는 것이다.
이 모델을 학습시키려면 어떠한 데이터가 필요한지 되돌아보자.
GPU는 병렬 연산 시, 시퀀스 길이가 동일해야 연산에 유리하다.
앞서 여태까지는 데이터를 이렇게 구성해왔다.

이 데이터는 다음 의미를 갖는다
- corpus[0]의 정답: corpus[1]
- corpus[1]의 정답: corpus[2]
- ...
입력 데이터와 출력 데이터의 시퀀스 길이가 양쪽 모두 1로 동일하다.
RNN은 원래 시퀀스의 길이에 대하여 예측에는 영향을 (거의) 안 받지만, 학습을 위한 대규모 연산의 경우에는 GPU 사용을 위해 시퀀스 길이를 맞춰주는 것이 유리하다.
즉, 학습을 빠르게 하려면 '고정된 길이'의 벡터가 필요하다.
그런데 현재 주어진 덧셈 식은 'a+b = c' 형태로, 숫자의 길이에 따라 입력 및 출력 벡터의 크기가 달라진다.
이를 다시 word2vec으로 하나의 벡터로 치환하는 과정은 간단하게 하기 어려울 것 같은데, 좀 더 간단한 방법이 없을까?
가변 길이 시계열 데이터를 미니배치로 학습하기 위한 가장 단순한 방법은 패딩을 이용하는 것이다.

우리는 이번 문제에서 0~999 사이의 숫자 2개만 더하기로 하자.
따라서 '+'까지 포함한 입력 문자의 최대 수는 7이 된다.
자연스럽게, 덧셈의 결과는 최대 4문자이다.(999+999=1998)
더불어 정답 데이터에도 패딩을 수행해 모든 샘플 데이터의 길이를 통일한다.
그리고 질문과 정답을 구분하기 위해 출력 앞에 구분자로 밑줄(_)을 붙이기로 한다.
그 결과, 출력 데이터는 총 5문자로 통일한다.
이처럼 패딩을 적용해 데이터 크기를 통일시키면 가변 길이 시계열 데이터도 처리할 수 있다.
그러나 원래는 존재하지 않던 패딩용 문자까지 seq2seq가 처리하게 된다.
따라서 패딩을 적용해야 하지만, 정확성이 중요하다면, seq2seq에 패딩 전용 처리를 추가해야 한다.
예를 들어 디코더의 경우, Decoder에 입력된 데이터가 패딩이라면 손실의 결과에 반영하지 않도록 한다.
이는 Softmax with Loss 계층에 마스크를 추가하면 가능하다.
한편, 인코더에 입력된 데이터가 패딩이라면 LSTM계층이 이전 시각의 입력을 그대로 출력하게 만들어야 한다.
즉, 적절한 조작을 통해 LSTM 계층이 마치 처음부터 패딩이 존재하지 않았던 것처럼 인코딩하게 할 수 있다.
참고로 학습 데이터는 "의미의 최소 단위"를 결정하는 것이 중요하다.
word2vec에서 단어 사이의 관계를 학습시켰듯, 이번엔 각 정수 한자리마다 의미를 부여했다.
덧셈 데이터셋
지금부터 아래와 같은 데이터셋을 가지고 seq2seq를 구현해나갈 것이다.
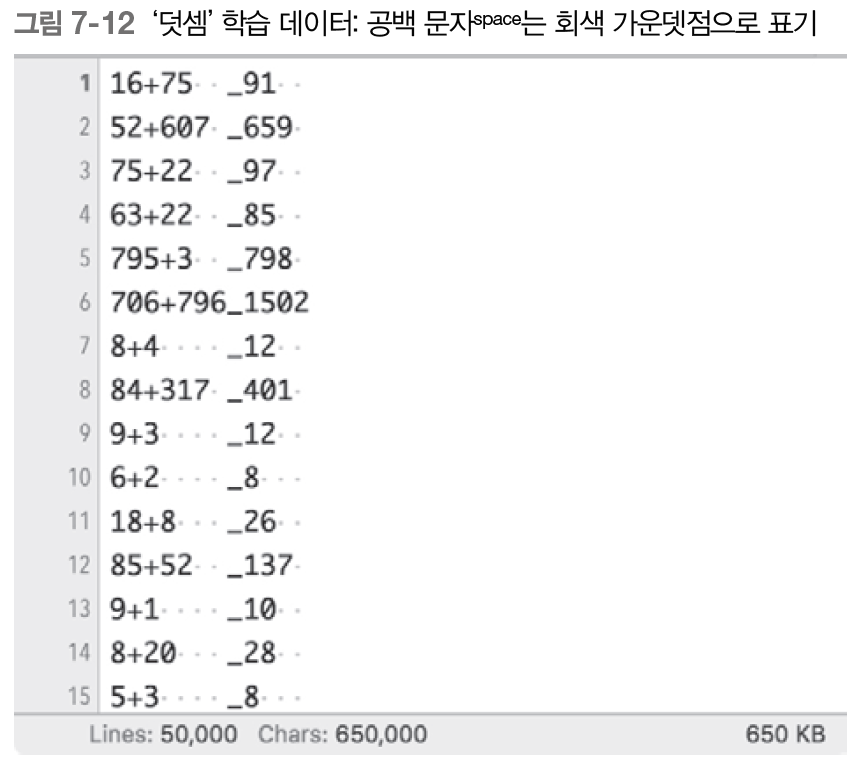
참고로, 이 학습 데이터는 케라스의 seq2seq 구현 예를 참고했다.
이 책에선, seq2seq용 학습 데이터를 파이썬에서 쉽게 처리할 수 있도록 load_data()와 get_vocab()이라는 2개의 메소드가 정의되어 있다.
load_data(file_name, seed)는 file_name으로 지정한 텍스트 파일을 읽어 텍스트를 문자 ID로 변환하고, 이를 훈련 데이터와 테스트 데이터로 나눠 반환한다.
seed는 이 메서드 내부에서 사용하는 시드값이다.
get_vocab() 메소드는 문자와 문자 ID의 대응 관계를 담은 딕셔너리를 반환한다.
실제로는 char_to_id와 id_to_char라는 2개의 딕셔너리를 돌려준다.
간단하게 실제로 사용하는 예를 보자.


정석대로라면 훈련용/검증용/테스트용으로 나눠야 하지만, 단순화를 위해 검증용 및 하이퍼파라미터 튜닝은 제외하였다.
seq2seq 구현
Encoder 클래스
인코더 클래스는 아래 그림처럼 문자열을 받아 벡터 h로 변환한다.

앞서 언급했듯, 인코더는 RNN을 이용해 구성한다.
이번에는 LSTM을 이용하자.

Encoder 계층은 오른쪽으로는 은닉상태와 셀을 출력하고, 위쪽으로는 은닉상태만 출력한다.
위 그림에서 보듯 Encoder는 마지막 문자를 처리한 후 LSTM 계층의 은닉 상태 h를 출력한다.
그리고 이 은닉 상태 h가 디코더로 전달된다.
우리는 시간 방향을 한꺼번에 처리하는 계층을 Time LSTM 계층이나 Time Embedding 계층으로 구현했다.
이를 이용해 표현하면 아래와 같다.

이제 Encoder 클래스의 구현을 살펴보자.
먼저 초기화 함수의 구현이다.

5장과 6장의 언어 모델은 "긴 시계열 데이터"가 하나뿐인 문제를 다뤘다.
TimeLSTM 계층의 stateful=True로 설정하여 은닉 상태를 유지한 채로 '긴 시계열 데이터'를 처리한 것이다.
한편, 이번에는 '짧은 시계열 데이터'가 여러개인 문제이다.
따라서 문제마다 LSTM의 은닉 상태를 다시 초기화한 상태(영벡터)로 설정한다.
이어서 forward()와 backward()이다.

먼저 forward에서는 마지막 시각의 은닉 상태만을 반환한다.
backward에서 dh는 디코더가 전해주는 기울기다. 인코더는 손실 함수에 대한 미분값을 디코더를 통해서만 알 수 있기에, 디코더에게서 dh를 받고 계산을 수행한다.
참고: 일반적으로 dout은 1로 시작했었다.
Decoder 클래스
다음으로 Decoder 클래스이다.

디코더는 위에서 설명했듯이 인코더에서 은닉상태 h를 받아 목적으로 하는 다른 시퀀스 데이터를 출력한다.
그리고 디코더 또한 RNN으로 구현된다.
이를 그림으로 나타내면 아래와 같다.

그림이 혼란스러울 수 있는데, 집중하고 보자.
언어 모델에서는 RNN이 출력하는 은닉 상태가 그 즉시 출력값이 됐었는데,
seq2seq에선 디코더가 출력하는 값이 최종 출력값이 된다.
- 출력 값의 순서가 일치해야 한다.
- 출력 값의 인덱스 별 값이 일치해야 한다.
- 이 예에선 첫번째 칸에 6, 두번째 칸에 2
- 그리고 이전 예측/정답 값을 현재 값의 입력으로 받아온다.
그래서 다음과 같이 정리된다. - 훈련 시에는, 정답 데이터를 이미 알고 있으므로, 입력 데이터를 즉시 정답값으로 넣어준다.
- 이때, 첫번째 값은 최초 시작을 알리는 구분문자'_'를 주었다.
- 테스트 시에는, 정답 데이터를 모르므로 최초 시작을 알리는 구분 문자 '_'만을 주고 예측을 수행한다.
원래 정답 데이터는 "_62"이지만, 위 그림에서는 입력 데이터를 ['_', '6', '2', '']로 주고,
이에 대응하는 출력은 ['6', '2', '', '']이 되도록 학습시켰다.
이제 Decoder가 문자열을 생성(예측)하는 흐름을 살펴보자.
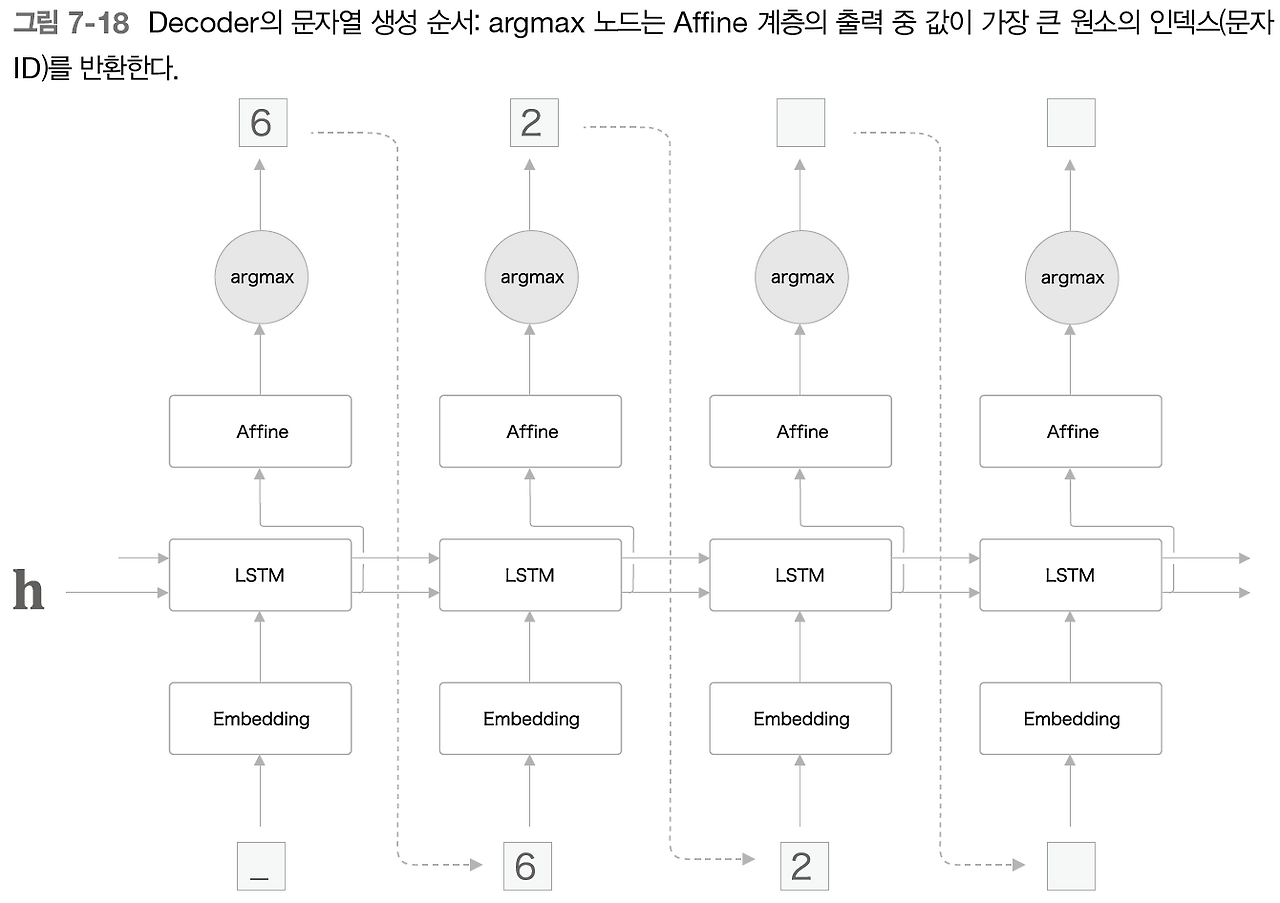
이제는 argmax라는 못보던 노드가 새로 등장했다.
바로 최댓값을 가진 원소의 인덱스(이번 예에서는 문자 ID)를 선택하는 노드이다.
이는 덧셈의 특징을 파악하고 넣은것인데, 덧셈은 결정론적인 작업이기 때문에 확률적으로 샘플링하지 않고 즉시 최댓값을 넣어준 것이다.
물론 학습 시에는 Softmax with Loss 계층이 필요하기 때문에, Decoder의 경우 예측 모델과 학습 모델의 순전파를 구분할 것이다.
그러니 Decoder 클래스의 구성을 아래와 같이 Softmax with Loss 계층을 제외시키고, 이 활성화 함수 계층은 위임하는 클래스인 Seq2seq 클래스가 갖고 있도록 하자.

이를 바탕으로 Decoder 클래스를 구현하면 아래와 같다.
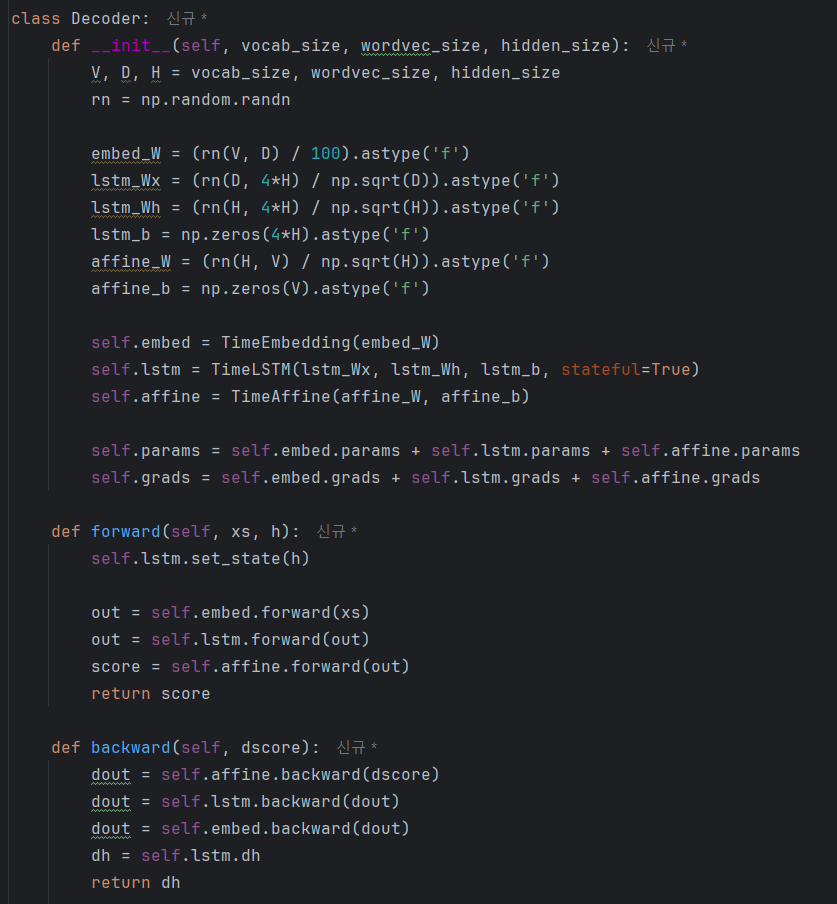
backward() 메소드는 위쪽의 Softmax with Loss 계층으로부터 기울기 dscore 을 받아 계층 순서대로 역전파를 진행한다.
이때 Time LSTM 계층의 시간 방향으로의 기울기는 TimeLSTM 클래스의 인스턴스 변수 dh에 저장되어 있다. 따라서 이 시간방향의 기울기 dh를 꺼내서 Decoder 클래스의 backward()의 출력으로 반환한다.
Time LSTM 계층의 구현은 해당 링크를 참고 바랍니다.
[밑바닥부터 시작하는 딥러닝] LSTM
본 내용은 밑바닥부터 시작하는 딥러닝 2도서를 참고하여 작성되었습니다. 밑바닥부터 시작하는 딥러닝 2 - 예스24직접 구현하면서 배우는 본격 딥러닝 입문서 이번에는 순환 신경망과 자연어
dev.go-gradually.me
이제 Decoder 함수의 문장 생성을 담당하는 generate() 메소드를 구현해보자.
앞서 언급한 것처럼, Decoder 클래스는 학습 시와 문장 생성 시의 동작이 다르다.

Seq2seq 클래스
마지막으로 Seq2seq 클래스의 구현이다.
이 클래스가 하는 일은 Encoder 클래스와 Decoder클래스를 연결하고, Time Softmax with Loss 계층까지 추가해 손실을 계산하는 것이 전부이다.
바로 코드를 보자.
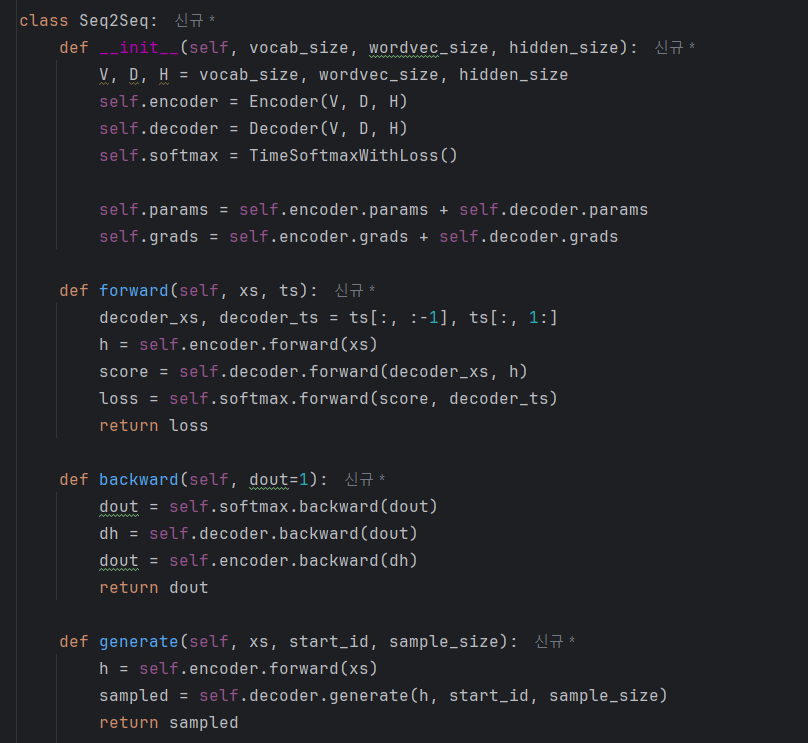
주가 되는 기능은 Encoder와 Decoder 클래스에 이미 구현되어 있다.
이 클래스는 각 기능들을 조립하는 역할을 수행한다.
이제 이 seq2seq를 통해 '덧셈' 문제에 도전해보자.
seq2seq 평가
seq2seq의 학습은 기본적인 신경망의 학습과 같은 흐름으로 이뤄진다.
- 학습 데이터에서 미니배치를 선택하고,
- 미니배치로부터 기울기를 계산하고,
- 기울기를 사용하여 매개변수를 갱신한다.
이를 코드로 구현하면 아래와 같다.
# coding: utf-8
import sys
sys.path.append('..')
import numpy as np
import matplotlib.pyplot as plt
from dataset import sequence
from common.optimizer import Adam
from common.trainer import Trainer
from common.util import eval_seq2seq
from seq2seq import Seq2seq
(x_train, t_train), (x_test, t_test) = sequence.load_data('addition.txt')
char_to_id, id_to_char = sequence.get_vocab()
vocab_size = len(char_to_id)
wordvec_size = 16
hidden_size = 128
batch_size = 128
max_epoch = 25
max_grad = 5.0
model = Seq2seq(vocab_size, wordvec_size, hidden_size)
optimizer = Adam()
trainer = Trainer(model, optimizer)
acc_list = []
for epoch in range(max_epoch):
trainer.fit(x_train, t_train, max_epoch=1,
batch_size=batch_size, max_grad=max_grad)
correct_num = 0
for i in range(len(x_test)):
question, correct = x_test[[i]], t_test[[i]]
verbose = i < 10
correct_num += eval_seq2seq(model, question, correct,
id_to_char, verbose)
acc = float(correct_num) / len(x_test)
acc_list.append(acc)
print('val acc %.3f%%' % (acc * 100))
x = np.arange(len(acc_list))
plt.plot(x, acc_list, marker='o')
plt.xlabel('epochs')
plt.ylabel('accuracy')
plt.ylim(0, 1.0)
plt.show()이제 이 실행 결과를 보자.

얼추 정답에 가까운 답을 내놓을 수 있게 되었다.
학습률은 이렇게 변해갔다.

이처럼 에폭을 거듭함에 따라 정답률이 착실하게 상승하는 것을 알 수 있었다.
이번 실험은 25에폭정도 수행했는데, 그 시점의 정답률은 10%정도였다.
일단 이번 학습은 여기서 끝내고, 같은 문제(덧셈 문제)를 더 잘 학습할 수 있도록 seq2seq를 개선해보자.
seq2seq 개선
이번에는 앞 절의 seq2seq 를 세분화하여 학습속도를 개선하고자 한다.
효과적인 기법이 몇 가지 있는데, 그중 2가지 개선안을 배워보고 결과까지 확인해보자.
입력 데이터 반전(Reverse)
첫 번째 개선안은 아주 쉬운 트릭으로, 아래 그림에서 보듯 입력 데이터의 순서를 반전시키는 것이다.
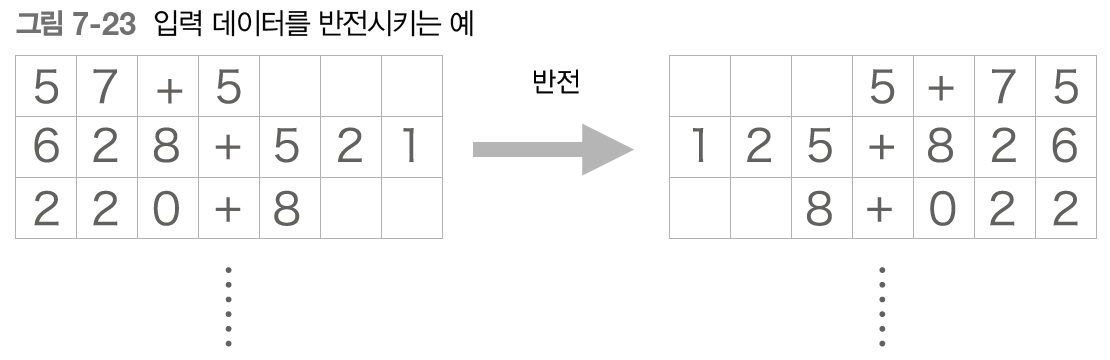
이 트릭을 사용하면 많은 경우 학습 진행이 빨라져서, 결과적으로 최종 정확도도 좋아진다고 한다.
관련 논문은 링크를 참고하세요.
백문이 불여일견, 한번 해보자.


이전보다 확연히 정답의 빈도가 올라갔다!
그 결과 정답률은 이렇게 달라졌다.

엿보기(Peeky)
이어서 seq2seq의 두번째 개션이다.
주제로 곧장 들어가기 전에, Encoder의 동작을 한번 더 살펴보자.
인코더의 출력 h는 디코더의 첫번째 시각의 LSTM 계층만 받는다.
사실 h는 디코더에게 필요한 정보가 모두 담겨 있는데, 이보다 디코더에게 중요한 데이터가 있을까?

여기서 seq2seq의 두번째 개선안이 등장한다.
중요한 정보가 담긴 Encoder 의 출력 h를 Decoder의 다른 계층+시각에도 전해주는 것이다.
이는 LSTM 계층과 Affine 계층 모두에게 인코더의 출력 h를 전달하고, 이를 그림으로 표현하면 아래와 같다.

관련 논문은 해당 링크를 참고 바랍니다.
그런데 위 그림에서는 LSTM 계층과 Affine 계층에 입력되는 벡터가 2개씩이 되었다.
이는 실제로 두 벡터가 연결(concatenate)된 것을 의미한다.
따라서 앞의 그림은 두 벡터를 연결시키는 concat 노드를 이용해 표현해야 정확한 계산 그래프이다.

그럼 PeekyDecoder와 PeekySeq2seq의 구현을 살펴보자.
import sys
sys.path.append('..')
from common.time_layers import *
from seq2seq import Seq2seq, Encoder
class PeekyDecoder:
def __init__(self, vocab_size, wordvec_size, hidden_size):
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
embed_W = (rn(V, D) / 100).astype('f')
lstm_Wx = (rn(H + D, 4 * H) / np.sqrt(H + D)).astype('f')
lstm_Wh = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_b = np.zeros(4 * H).astype('f')
affine_W = (rn(H + H, V) / np.sqrt(H + H)).astype('f')
affine_b = np.zeros(V).astype('f')
self.embed = TimeEmbedding(embed_W)
self.lstm = TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful=True)
self.affine = TimeAffine(affine_W, affine_b)
self.params, self.grads = [], []
for layer in (self.embed, self.lstm, self.affine):
self.params += layer.params
self.grads += layer.grads
self.cache = None
def forward(self, xs, h):
N, T = xs.shape
N, H = h.shape
self.lstm.set_state(h)
out = self.embed.forward(xs)
hs = np.repeat(h, T, axis=0).reshape(N, T, H)
out = np.concatenate((hs, out), axis=2)
out = self.lstm.forward(out)
out = np.concatenate((hs, out), axis=2)
score = self.affine.forward(out)
self.cache = H
return score
def backward(self, dscore):
H = self.cache
dout = self.affine.backward(dscore)
dout, dhs0 = dout[:, :, H:], dout[:, :, :H]
dout = self.lstm.backward(dout)
dembed, dhs1 = dout[:, :, H:], dout[:, :, :H]
self.embed.backward(dembed)
dhs = dhs0 + dhs1
dh = self.lstm.dh + np.sum(dhs, axis=1)
return dh
def generate(self, h, start_id, sample_size):
sampled = []
char_id = start_id
self.lstm.set_state(h)
H = h.shape[1]
peeky_h = h.reshape(1, 1, H)
for _ in range(sample_size):
x = np.array([char_id]).reshape((1, 1))
out = self.embed.forward(x)
out = np.concatenate((peeky_h, out), axis=2)
out = self.lstm.forward(out)
out = np.concatenate((peeky_h, out), axis=2)
score = self.affine.forward(out)
char_id = np.argmax(score.flatten())
sampled.append(char_id)
return sampled
class PeekySeq2seq(Seq2seq):
def __init__(self, vocab_size, wordvec_size, hidden_size):
V, D, H = vocab_size, wordvec_size, hidden_size
self.encoder = Encoder(V, D, H)
self.decoder = PeekyDecoder(V, D, H)
self.softmax = TimeSoftmaxWithLoss()
self.params = self.encoder.params + self.decoder.params
self.grads = self.encoder.grads + self.decoder.grads이제 이 peeky 콤보를 적용하고

실행 결과를 살펴보자.

정답률의 변화는 얼마나 차이나게 되었을까?

큰 폭의 발전을 이룬 것을 확인할 수 있었다!
참고로, 이번 절에 수행한 개선은 '작은 개선'이다.
진정한 개선은 "어텐션"과, "Attention is All you need"로 이어지는 "트랜스포머"에 있다.
이번 절의 실험은 주의해야 한다.
Peeky 를 이용하게 되면 우리의 신경망은 가중치 매개변수가 커져서 계산량도 늘어난다.
따라서 이번 절의 실험 결과는 커진 매개변수만큼의 '핸디캡'임을 감안해야 한다.
또한, seq2seq의 정확도는 하이퍼파라미터에 영향을 크게 받는다. 예제의 결과는 믿음직했지만, 실제 문제에서는 효과가 달라질 것이다.
seq2seq를 이용하는 애플리케이션
그럼 이 seq2seq를 어디에 사용할 수 있을까?
요새는 전부 트랜스포머로 대체되었기 때문에, 간단한 이미지만 남깁니다.
챗봇

알고리즘 학습

이미지 캡셔닝
seq2seq를 이용한 이미지 캡셔닝의 경우, CNN이 인코더 대신 들어간다.
이때 CNN의 최종 출력은 feature map으로, 3차원(높이, 폭, 채널) 데이터를 가지고 있다.
따라서 이를 LSTM이 처리할 수 있도록 평탄화(flattening)한 후, 완전연결인 Affine계층에서 변환을 수행한다.
그런 다음 변환된 데이터를 Decoder에 전달하면 지금까지와 같은 문장 생성을 수행할 수 있다.


이번 장에서 배운 것
- RNN을 이용한 언어 모델은 새로운 문장을 생성할 수 있다.
- 문장을 생성할 때는 하나의 단어(혹은 문자)를 주고 모델의 출력(확률분포)에서 샘플링하는 과정을 반복한다.
- RNN을 2개 조합함으로써 시계열 데이터를 다른 시계열 데이터로 변환할 수 있다.
- seq2seq는 Encoder가 출발어 입력문을 인코딩하고, 인코딩된 정보를 Decoder가 받아 디코딩하여 도착어 출력문을 얻는다.
- 입력문을 반전시키는 기법(Reverse), 또는 인코딩된 정보를 Decoder의 여러 계층에 전달하는 기법(Peeky)은 seq2seq의 정확도 향상에 효과적이다.
- 기계 번역, 챗봇, 이미지 캡셔닝 등 seq2seq는 다양한 애플리케이션에 이용할 수 있다.
- 인코더
- 디코더
- LSTM
- 어텐션
- 패딩